Google Data Scientist Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
A simple solution to a Google Data Scientist interview question requiring aggregation and window functions.
In this article, we’re going to look at one of the data scientist interview questions from Google and answer it through a simple problem-solving process you can apply to any other data science challenge. Read on to learn how we build out and execute a framework to answer data science interview questions through logical, manageable, and actionable steps.
Google is one of the largest technology companies in the world, started in 1998, with its famous search engine. Now Google has over 250 internet-related services and products including hardware, software, online advertising, and cloud computing. It’s part of the big five American IT Companies along with Facebook, Amazon, Apple, and Netflix and employs almost 140,000 people globally.
Data Science Positions at Google
Data is the main input and output for most of Google’s products. As such, data scientists operate across many of the teams at Google ranging from finance, operations, engineering, sales, support, marketing, strategy, and people. This results in a variety of different responsibilities depending on which team you’ll work with.

Data Scientist positions at Google require skills with statistical software such as R or Python, database languages such as SQL, machine learning, statistical data analysis, data modeling, and others. They also typically involve looking at large quantities of data to gain insights, interacting cross-functionally, making business recommendations for Google’s products.
Concepts Tested in Google Data Scientist Interview Questions
Database language skills you’d have to use in the Google Data Scientist Interview questions include:
- Counting data and other aggregation functions
- Ranking data over an ordering of some component of the data
- Making assumptions about your data and discarding irrelevant columns
The problem we’re solving in this article requires the use of all these abilities, and, through this practice question, you’ll be in a position to leverage them in your code solutions during an interview or when answering other questions on the StrataScratch platform.
Google Data Scientist Interview Question
Activity Rank
This is a real question a data scientist interviewer at Google asked a candidate to solve for them. It’s titled “Activity Rank”, and the goal is to find which users are sending the most emails and ranking the users based on discrete email data.


Link to Problem: https://platform.stratascratch.com/coding/10165-activity-rank
This Google data scientist interview question has a hard difficulty because it requires a careful and precise usage of the count aggregation and rank window functions. As with most questions, there are several ways to answer, but we want to solve this question in a way which displays a mastery of SQL concepts while being flexible enough for varying datasets.
Framework to Solve the Problem
It’s important to have a repeatable framework you use to solve a data science question. We have a basic three-step framework we use for all the data science interview questions on StrataScratch, and it involves understanding your data, formulating your approach, and executing your code.
- Understanding the data involves looking at all the columns of email data the interviewer gives and making assumptions based on them. If you can’t understand the data through the schema, ask for some sample email data. With a few rows, you might be able to match values to the columns and better understand the tables.
- Formulating an approach involves building out logical steps to solving the problem before translating them into code. Think of all the functions you’d need to analyze the email data then list them down, even if they’re not in the right order yet. As you build out your code outline, walk through it with the Google interviewer, so they understand your thought process and can provide any relevant feedback.
- Code execution involves writing your code down. At this point, you’ll turn your formulated steps into functional SQL code. You’ll want to avoid too simple or too complicated a solution since, in many cases, these types of solutions may be insufficiently generic for a variety of datasets. You’ll want to continue speaking through your solution with the Google interviewer to display your problem-solving abilities.
Understand Your Data
We’ll first need to take a look at the data Google gives us and build assumptions off it. Keep in mind you won’t always have access to real data or a way to execute your code during Google interviews. Instead, you’ll have to look at the schema and the information the interviewer gives you to make your assumptions and formulate your code.
In this particular interview question, we only have one table to analyze.
google_gmail_emails
| id | int |
| from_user | varchar |
| to_user | varchar |
| day | int |

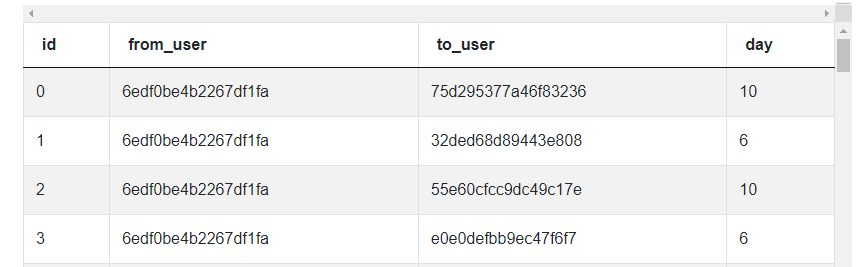
This google_gmail_emails table presents a row for each email interaction. We see from which user the email comes, to which user it goes, and what day they sent the email. To begin, we can make two assumptions about this data:
- We won’t need the id, day, or to_user columns.
- We’ll use the from_user as the column we use to determine email counts by user.
Solution:
Formulate Approach
Next we list general, logical, basic steps we’ll later turn into code. We keep it high-level to outline our potential solution and then get more complex during code execution. Here are the steps we’ll follow for this question:
- Query the data table ignoring the irrelevant columns to get a count of emails per user
- Use a ranking window function such as ROW_NUMBER() to rank the email counts by user and order them
Emails Sent Per User
We must turn these general steps into working SQL code. We’ll begin by querying the google_gmail_emails table and getting a count of how many emails each user sends. We already assumed we can discard the id, to_user, and day columns in our SELECT statement. As part of our query, we use the COUNT() aggregation function to calculate the email count, and, as with any aggregation function, we must GROUP BY a summary column which, in this table, is the from_user.
MARKDOWN:
SELECT from_user,
COUNT(*) AS total_emails
FROM google_gmail_emails
GROUP BY 1
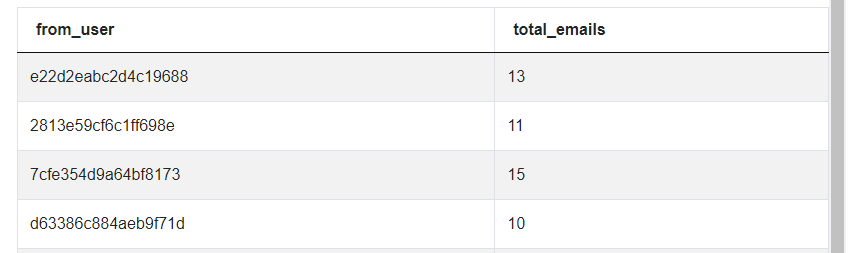
With this code block, we already have a total email count per user. However, we can see it’s not ranked in any order, so our next step involves ranking over the total email counts in the proper ordering.
Ranking and Ordering Total Email Counts Per User
The question is very specific about how ranking and ordering must look, so we must apply a unique rank to every row even in the case of ties and apply a descending order to the total email counts.
For ranking, we’ll use the ROW_NUMBER() window function to avoid skipping or repeating ranks. With ranking window functions, you typically have to rank over an ordering of data, and, in this solution, we’ll rank over the descending order of total email counts by again using the COUNT(*) aggregation function.
SELECT from_user,
COUNT(*) AS total_emails,
ROW_NUMBER() OVER (
ORDER BY COUNT(*) DESC) AS ntile
FROM google_gmail_emails
GROUP BY 1
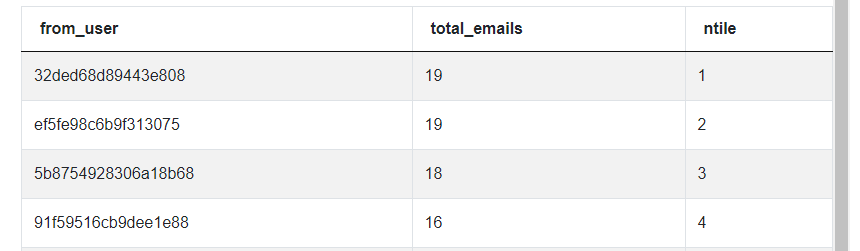
Now we have the correct ordering and respective ranking of our total email counts which represents the correct output.
Conclusion
In this article, we figured out a Google data scientist interview question with a fairly basic query. While there are several other ways to answer this question, we provided one of the simplest and most efficient solutions. One useful challenge would be adding to this query to determine the percentile for each of the total email counts. We also recommend using the StrataScratch platform to see if you can come up with alternative solutions which are more creative, efficient, or simple.
We also recommend checking out our other posts "The Ultimate Guide to Become a Data Scientist at Google", "Google Data Scientist Salary" and "Google Data Scientist Position Guide" to find out what it means to be a data scientist at Google.
Beyond practicing this Google data scientist interview question, you can work on many other interview questions on the StrataScratch platform. This will help you advance your skills and interview abilities while also giving you access to the StrataScratch community where you can share your solutions, view others’ solutions, and collaborate on challenges with other users.
Share


