Go-to Guide to Currying in Python


 Written by:
Written by:Nathan Rosidi
Master Currying in Python for Efficient Data Processing and Machine Learning. Ideal for data scientists and Python developers looking to enhance their skill set.
You've probably come across the term "Currying" in your programming adventures. Though it sounds culinary, its application in Python is a technique that can significantly tidy up your code.
Currying is a concept that breaks down functions into simpler, single-argument bits, which can be pieced together to form robust pipelines, streamlining your data processing tasks. It's where the magic of functional programming truly shines.
In this article, we’ll explore the basics of currying, its implementation, and its crucial role in building efficient data processing pipelines, especially in machine learning projects. We'll also touch upon the common pitfalls to avoid when employing currying in your code. Buckle up, and let’s get started!
Currying in Python
In the following sections, we will explore the basics of currying along with its implementation. Next, we will go into how currying can be used in building pipelines. Although it's a potent tool, incorrect usage can lead to pitfalls, which we will discuss at the end of this section.
But first, let’s discover together, the reasons for using currying and expand them to make things clearer.
Why Use Currying in Python?
Currying offers several advantages in programming and data processing tasks. Here are a few reasons why one might consider using Python curry.
- Modularity: Currying helps in breaking down complex functions into simpler functions, promoting modularity.
- Code Reusability: By creating functions with fewer arguments, currying aids in making code more reusable and configurable.
- Lazy Evaluation: Currying supports lazy evaluation, where the evaluation of expressions is delayed until their results are needed.
- Functional Composition: Currying is foundational for functional programming techniques like function composition, allowing for the creation of sophisticated data processing pipelines with simpler, composable functions.
- Enhanced Readability: When used judiciously, currying can lead to code that is more readable and easier to understand.
Basics of Currying in Python
Currying is the process of transforming a function that takes multiple arguments into a series of functions that each take a single argument. In Python, this can be achieved through nested functions.
To distinguish between non-curried and curried versions of the functions, let’s check the same functions below.
Original Function (non-curried):
def multiply(a, b, c):
return a * b * c
Curried Version:
def curried_multiply(a):
def next(b):
def final(c):
return a * b * c
return final
return next
But how can you define currying. Above we used nested function, but we have one more option.
Implementation of Currying in Python


There are two different ways of implementing currying, by using nested functions or partial function.
Using Nested Functions
Currying can be implemented in Python using nested functions. Here’s a snippet to illustrate this.
def curry_multiply(a):
def next(b):
def final(c):
return a * b * c
return final
return next
# Usage:
curry_multiply(2)(3)(4)
Here is the output.


In this snippet, curry_multiply is a curried function that takes one argument at a time, eventually multiplying three numbers together.
Using functools.partial
Python provides a module named functools which has a method partial that allows for partial application of a function, which is a form of currying. Here’s a snippet to demonstrate this.
import functools
def multiply(a, b, c):
return a * b * c
# Partial application
multiply_by_two = functools.partial(multiply, 2)
multiply_by_two_and_three = functools.partial(multiply_by_two, 3)
result = multiply_by_two_and_three(4)
resultHere is the output.
In this example, functools.partial is used to fix the first argument of the function multiply, generating a new function multiply_by_two, which is then partially applied again to generate multiply_by_two_and_three, and so on.
Building Pipeline with Python Curry
Currying holds a significant place in building efficient data processing pipelines in machine learning (ML) projects. It involves breaking down a function with multiple arguments into a sequence of single-argument functions.
This not only enhances the modularity and readability of the code but also facilitates the construction of data transformation pipelines in a more organized manner.
In ML, preprocessing is a critical step that ensures the data fed into models is of good quality and adheres to the assumptions required by many algorithms. Three common preprocessing tasks are the removal of missing values (NA removal), scaling of features (normalization), and outlier removal. Let's go into the importance of each step.
1. NA Removal
Missing values in the dataset can lead to incorrect or biased analysis. Most ML algorithms require complete datasets to function correctly. Hence, handling missing values is crucial before proceeding with further analyses.
2. Scaling
Features on vastly different scales can cause issues with algorithms that rely on distance or gradient calculations. Normalization, a type of scaling, transforms features to a standard scale, ensuring each feature contributes equally to the computation.
3. Outlier Removal
Outliers can skew the dataset and affect the performance of ML models. Identifying and removing outliers helps in obtaining better and more reliable model predictions.
Now, let's look at a practical example that shows how currying can be used to build a pipeline to perform these preprocessing steps on a synthetic dataset.
# Import necessary libraries
import pandas as pd
import numpy as np
from scipy import stats
# Create a synthetic dataset
np.random.seed(0)
data = pd.DataFrame({
'Feature1': np.concatenate([np.random.normal(0, 1, 95), np.random.normal(10, 1, 5)]), # Outliers
'Feature2': np.random.normal(50, 10, 100),
})
data.iloc[::10, :] = np.nan # Introduce NA values
# Define curried functions
def remove_na(axis):
def inner(data):
return data.dropna(axis=axis)
return inner
def filter_outliers(threshold):
def inner(data):
return data[(np.abs(stats.zscore(data, nan_policy='omit')) < threshold).all(axis=1)]
return inner
def normalize():
def inner(data):
return (data - data.mean()) / data.std()
return inner
# Create the pipeline
def pipeline(data):
return normalize()(filter_outliers(3)(remove_na(0)(data)))
# Original Data
print("Original Data:\n", data.describe())
# Processed Data
processed_data = pipeline(data)
print("\nProcessed Data:\n", processed_data.describe())
In the code above, a synthetic dataset with two features is created. Feature1 contains outliers, and NA values are introduced in both features at every 10th row. Three curried functions remove_na, filter_outliers, and normalize are defined for data preprocessing tasks.
A pipeline function chains these curried functions together to form a data processing pipeline. The described method provides summary statistics of the original and processed data, allowing a comparison before and after preprocessing. Now let’s see the output of the code above.

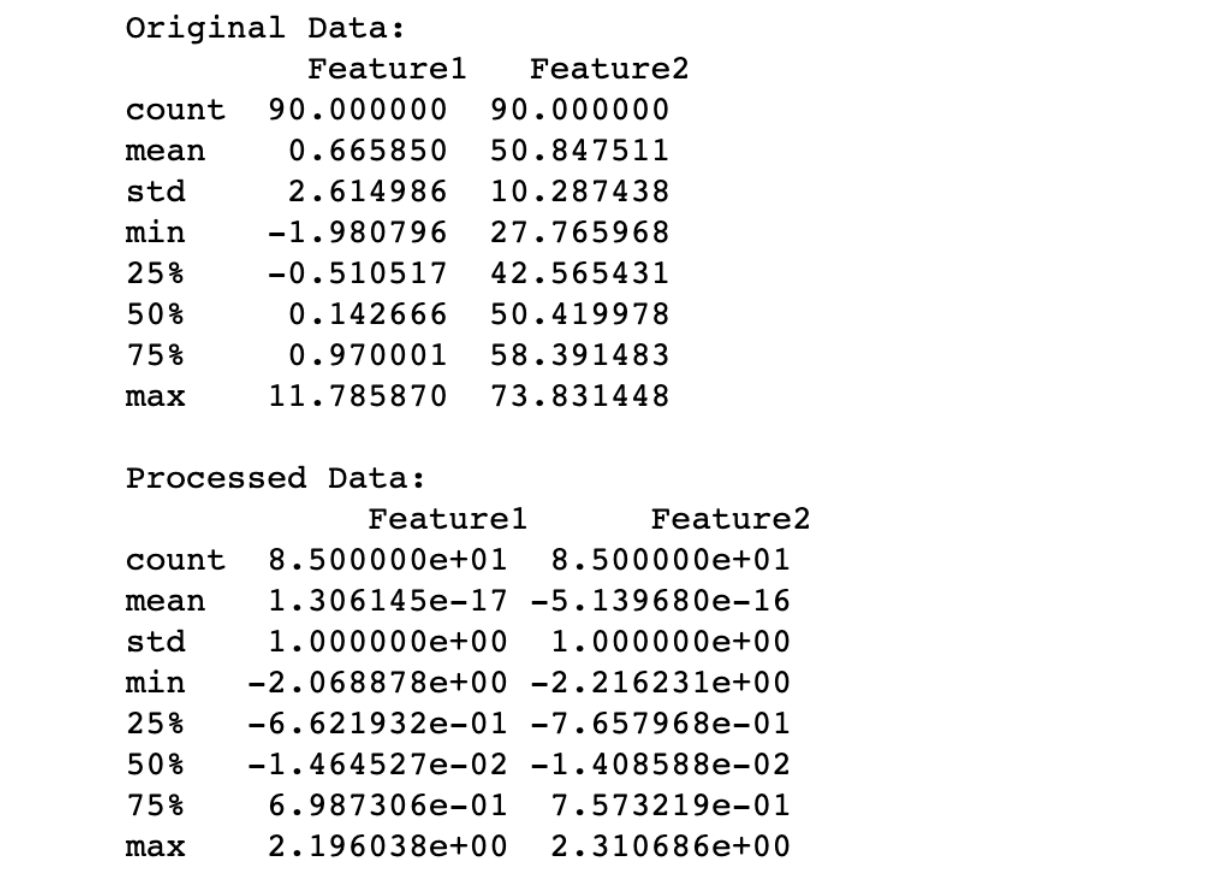
The output provides a clear comparison between the original data and the processed data after applying the specified curried functions through the pipeline. Here's how you can evaluate the output:
NA Removal
- In the original data, the count is 90 for both features, indicating that 10 rows with NA values have been excluded from these statistics.
- NA removal is the first step in the pipeline, so the processed data's count reflects this removal.
Outlier Removal
- In the original data, Feature1 has a maximum value of around 11.79, which is an outlier.
- After processing, the max value in Feature1 is around 2.20, indicating that outliers have been successfully filtered out.
Normalization
- In the original data, the means of Feature1 and Feature2 are around 0.67 and 50.85, with standard deviations of around 2.61 and 10.29, respectively.
- After processing, the means of both features are essentially zero, and the standard deviations are 1. This indicates that the data has been successfully normalized to a standard scale.
Data Distribution
- The quartiles (25%, 50%, 75%) in the processed data are symmetric around the mean (which is 0), indicating a standard normal distribution.
- This is a result of the normalization step, which scales the data such that it has a mean of 0 and a standard deviation of 1.
Data Reduction
- The count of data points has reduced from 90 to 85 due to the outlier removal step. This reduction in data points is a trade-off for removing noise and ensuring more reliable downstream analysis.
In summary, the pipeline has effectively handled missing values, removed outliers, and normalized the dataset, making it more suitable for further analysis or modeling.
This preprocessed data now adheres to common assumptions made by many statistical models and machine learning algorithms, such as having features on a similar scale and being free of outliers and missing values.
Possible Pitfalls of Currying in Python
Now we have listed many advantages of currying; on the other hand, there might be pitfalls in using it if you don’t follow certain steps. So don’t skip this section, to ensure you avoid these issues.
Readability
While currying can enhance modularity and readability, there's a threshold beyond which it can make the code more complex and harder to understand.
Excessive use of currying may lead to a codebase filled with many small, nested functions, making the code flow less intuitive, especially for those not familiar with the concept of currying.
Debugging
Currying can introduce challenges in debugging. When a bug occurs in a deeply curried function, tracing the source of the error through a series of nested functions can be like finding a needle in a haystack.
The nested function structure can obscure the flow of data and the sequence of operations, making it difficult to identify and fix bugs.
Moreover, debugging tools and error stack traces might not provide clear insights when dealing with heavily curried functions, extending the time and effort required to debug and fix issues.
Conclusion
We've gone through the basics of currying in Python, its implementations, and its important role in building data pipelines. This journey showed how currying can improve code simplicity, reusability, and readability, making way for better-structured code.
By using Python currying, you're not just adopting a coding technique; you’re moving toward a style of programming that values simplicity and effectiveness. Mastering such concepts not only improves your coding skills but also gives you an edge in the fields of data science and machine learning.
Now that you've looked into the details of Python currying function, why not test your new knowledge? Head over to our platform and explore Python interview questions designed not only to reinforce your understanding but also to prepare you for questions you might face in your next interview. See you there!
Share


