From Data Collection to Model Deployment: 6 Stages of Data Science Project


 Written by:
Written by:Nathan Rosidi
You need to stand out from the thousands of your data science peers. Here’s how to use the six stages of the data science projects to do that.
In today’s article, we’ll walk you through the six crucial stages of a data science project. Why are these stages and data science projects, in general, important?
Let’s answer by asking the questions. Did you know that, according to LinkedIn, the machine learning engineer title is the fourth fastest-growing job?
And did you know that Glassdoor ranks data science among the top three best jobs in the USA?


Now you know. In these high-demand circumstances, it’s essential to stand out. On average, the recruiters spend only six seconds looking at your resume.
So how do you make an instant impression? By doing novel projects and showcasing the skills all data scientists should have.
The projects usually go through these six stages.


They are the same ones we covered in our YouTube video.
Stage 1: Data Collection
With data volumes tripling by 2025, it’s crucial that you know how to obtain, collect, and clean data.

Reading from file sources, scraping the web, or using APIs; it doesn’t matter – the goal is to amass quality data for your project.
But why do you need so much data? Well, the final stage of a data project will be model building and deploying it to production.

So increasingly, this model's performance will be highly important. One way to improve its performance is by collecting more data.

The more data you have, the better chance is that your model will perform well.

Here are three ways to collect data:
- Import a CSV file and read data that way.
- Scrape data from the web, which is getting so much easier these days with Chat GPT.
- Collect data from an API
My vote is to go to the API route. Learning how to work with an API is highly valued as a data science skill. It’ll also give you all the experience you need to work with enterprise tools.
Stage 2: Building a Data Pipeline
After collecting our data, we need to transform it. This stage is often called data cleaning or data wrangling. Its purpose is to ensure that our data is in the right format and quality for our analysis.
For example, if you have data with a bunch of NAs or missing values, you have to figure out a way to handle all of this missing data.

That could be getting the average, keeping them as missing values, or just replacing them with the minimum or the maximum value. All of these small systemic changes to the data will help you in the later stages of analysis.
Step 3: Data Exploration
This is the stage where you get to know your data. You can do that by using the functions like head(), describe(), and info() in Python. Yes, you can understand the dataset structure and content this way. However, that’s just beginner-level data science; everyone already knows how to do this. Remember, you need to stand out with your knowledge.
What you really want to do is understand if the data is appropriate for the specific ML model that you’re trying to build. In other words, understand your data's distributions,

normalities, outliers,

and other variables.
The data cleaning and exploration phases should take up about 60 percent of your time on the project.
Stage 4: Data Visualization
Visualizations bring your data to life. It can also be used to further your data exploration phase. Tools like Matplotlib, seaborn, and Tableau can help you detect outliers and understand correlations visually.
Here’s an example of looking at distributions.

Here’s another example of looking at feature correlations.
All of this could be used to understand your data and build your models.
And if you’re not building a model, then your work might end here. You can create a Tableau dashboard with the data you have, but I’d consider this a data analyst project, not necessarily a data science project.
If you’re into data analysis, here are some suggestions for the Data Analytics Projects you can do.
Stage 5: Model Building
This is where the data science project diverges from the data analysis project.
The heart of our project!
From choosing the suitable algorithm

to evaluating its performance,

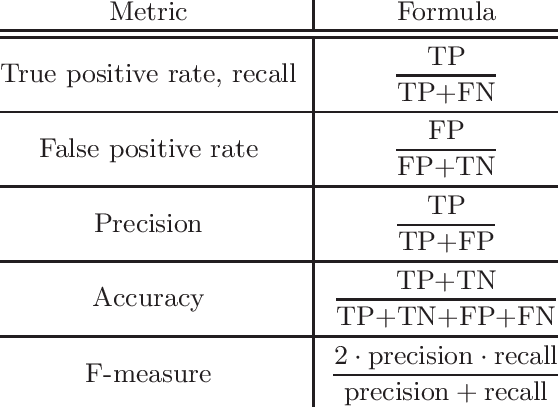
you’re using this stage to make accurate predictions.
There’s a systemic approach to this stage for any data science project consisting of these five steps.

It boils down to choosing the right algorithm that works best for your data. That’s why we do all of the data exploration stuff in the beginning stages.
Then, you’ll need to split the dataset into training and test datasets; It helps train your models.
And then you’ll A/B test, but in terms of trying to find the best-performing algorithm and use it to boost the model performance. This brings us to our last step, which is to evaluate your model’s performance using metrics like precision, recall, mean squared error…you know, the standard stuff.
Stage 6: Model in Production
When you’ve picked your model, it’s time to deploy it into production. This means going above and beyond the standard Jupiter notebook. 90% of data scientists in the making stop once they build the model in a notebook. But when you start working in the industry, you’ll see that many data scientists will actually release their models into production. I advise you to do this and to showcase your skills.
Whether or not you’re working with Flask, Django, Ruby on Rails, Shiny, or other platforms to host your model, the goal is to make the model accessible to users so you can get feedback and show off your skills.
What I would also try to do is to deploy your model on the cloud. Many companies use cloud infrastructure, so getting familiar with one, like AWS, GCP, or Azure, might help differentiate yourself amongst the hundreds, if not thousands, of applicants to get a job.
Conclusion
There you have it: from collecting data to deployment. Each stage is a step towards creating impactful projects that will help you stand out.
Also helping in that mission is building a project portfolio. Yeah, I know it’s difficult to decide which projects to include. Well, here are some data science projects that deserve that.
Share


