Facebook Python Interview Questions


Categories:
 Written by:
Written by:Nathan Rosidi
This Facebook python interview question will test your ability to use joins, perform transformations and calculations, and address edge-case scenarios.
We’re back with another Python interview question from Facebook / Meta. We will solve this question using our 3-step framework that can be used to solve any python interview questions.
Facebook Python Interview Question
Last Updated: July 2022
The CMO is interested in understanding how the sales of different product families are affected by promotional campaigns. To do so, for each product family, show the total number of units sold, as well as the percentage of units sold that had a valid promotion among total units sold. If there are NULLS in the result, replace them with zeroes. Promotion is valid if it's not empty and it's contained inside promotions table.
Link to the question: https://platform.stratascratch.com/coding/2123-product-families
Video Solution:
This Facebook python interview question revolves around the concept of promotional campaigns. In solving the problem, we are analyzing how each of the product families is selling, with and without promotions applied.
We are seeking a result table that shows all the product families, their corresponding total units sold as well as the percentage of units sold under a valid promotion. A valid promotion is defined in the problem statement as ‘not empty’ and ‘contained within the promotions table’.
Looks pretty straightforward. The trick is to transform the data provided into the desired format for us to display. For that to happen, we will need to look into the tables provided.
Always begin your solution by exploring the dataset.
Framework to solve this Facebook python interview question

1. Exploring the Dataset
Meta has provided three tables, viz., facebook_products, facebook_sales_promotions, and facebook_sales.
There’s a lot of information available in those tables, so we need to distinguish and prioritize what columns or relationships to investigate during the interview. To preview the tables given, we can use the head() function. If you are practicing on our StrataScratch platform, however, the table can be previewed using the ‘Preview’ button.
The first table, facebook_products, contains information related to the products. It includes supplementary information such as class, brand, category, family, and more attributes like whether the product is low-fat and recyclable.
It has the following schema:


Run the code below to view a preview of the table:
facebook_products.head()
Upon previewing the table using the head() function, we can see the following table:
The second table, facebook_sales_promotions, is a table dedicated to promotions available. It contains the start and end dates of the promotions, the media channel used to promote them, as well the cost of these campaigns.
The schema of the table is as follows:

Run the code below:
facebook_sales_promotions.head()
A preview of the table looks like this:
Thirdly, we have got the facebook_sales table which has the following schema:

Preview the table by running the following code:
facebook_sales.head()As you explore the schema and datasets provided, notice the common columns between these tables. Specifically, they are:
- product _id - facebook_sales and facebook_products tables
- promotion_id - facebook_sales and facebook_sales_promotions tables
Make it a practice to recognize the common columns as they help relate the tables later when we are figuring out an approach to solve this Facebook python interview question, which brings us to the next step.
2. Writing Out the Approach
Now that we have formed a better idea of our datasets let’s formulate our approach by identifying the high-level steps to our solution. It’s always good to have a plan before the execution so let’s not code anything just yet!
From the question, we figured out that the output table must contain three columns: Product Family, Total Units Sold, and Percentage of Units Sold Under Valid Promotion.
Let’s create a narrative that will help us navigate through this Facebook python interview question.
For each product family, we need the units sold in total and the percentage of these units sold under a valid promotion. To ensure the promotions are valid, we will need to cross-check the ‘promotion_id’ in the facebook_sales table with the ‘promotion_id’ in the facebook_sales_promotions table.
Therefore, we need to use data from multiple tables, so we need to merge these tables to identify the product family and the validity of each sales promotion.
Let’s list out the steps we are going to take.
- The first step in our approach is to identify which ‘product_family’ the ‘product_id’ from the facebook_sales table belongs to. We can achieve this by merging the facebook_sales and facebook_products tables.
- Next, we will create a new column to identify the sales made under valid promotions.
- Once the valid promotions are identified, we will split the merged table into valid and invalid promotion sales.
- Now, for each subset, we will compute the total units sold for each product family.
- We will then merge these subsets into one main table.
- We will then fill the null values with zeroes to avoid errors later on.
- We can now calculate the total sales per product family.
- Now that all the necessary information is available for the percentage calculation, we will compute the percentage of units sold under promotion.
- Finally, we will select the three columns mentioned earlier and replace any null values with zeroes.
3. Coding the Solution
Now that we have the approach written down, it is time to translate them into code.
1). Identify the product family by joining the products and sales table
Firstly, let’s merge the facebook_products and facebook_sales tables on the common column between them, i.e., product_id. By default, we would’ve gone for an inner join, but in this, that’s not such a good idea.
Edge Case:
Remember that this Facebook python interview question asks us to make calculations for all the available product families. In an ideal setting, the various product families would be well-represented in the sales table. But in a realistic setting, it may not be the case.
We need to take into account phased-out items and newly introduced items that would have periods wherein there would be no sale. These would be entered in the table as NULL values. We will act upon this edge case later in our solution by filling these NULL values with 0s to avoid errors.
Regardless of whether a sale was made or not, all product families need to be handled in our solution. So, we will use an ‘outer’ join instead of an inner join.
import pandas as pd
merged = facebook_sales.merge(facebook_products, how="outer", on="product_id")
The output of the table is as follows:


You could counter this approach with one where the facebook_products table is the base table and merged with facebook_sales using a left join. This is another viable approach to ensure that all the product families are being captured.
2. Create a new column identifying the sales made under a valid promotion
Next, we want to establish the promotion validity of each sale and create a new column for this information.
To mark a promotion as ‘valid’, we will need to ensure that the promotion_id in the sales table is not empty and that the promotion_id is also contained in the promotions table.
Of course, there are different ways of getting this done. A smart trick is to use a map-lambda combination. For those of you who are not familiar, a map takes in an iterable like a list and transforms each item of that iterable by applying the function specified.
We only need a temporary function here, so we can use a lambda function instead of defining a whole new function separately. As an added bonus, lambda allows us to specify the function in a single line of code!
Now the merged table should contain the main requirements of our solution - the product family, the number of units sold, and an indication of the promotion validity.
Digging deeper into the target table once more, the total units sold and percentage of sales on promotion can be calculated as:
Code below as a comment (under “OUTPUT: product_family | n_sold | perc_promotion”)
# product_family | SUM(units_sold) | SUM(units_sold_valid) / SUM(units_sold)*100Now, we will create a new column named valid_promotion which will be marked as True if the promotion is valid and ‘False’ if it isn’t. A valid promotion was defined by two factors:
- The promotion_id cannot be missing or null
- The promotion_id should also exist in the facebook_sales_promotions table
The first condition can be checked by using the pandas function, isna(). So we will need to import the pandas first. The latter can be efficiently achieved by getting the full list of unique promotion_ids from the promotions table and checking if it exists in that list.
Let’s now write these two conditions in code as shown below:
merged['valid_promotion'] = merged.promotion_id.map(lambda x: \
not pd.isna(x) and x \
in facebook_sales_promotions.promotion_id.unique())
The output of this step produces a table that contains a table containing only one column containing TRUE and FALSE values corresponding to whether the promotion_id was valid or not.

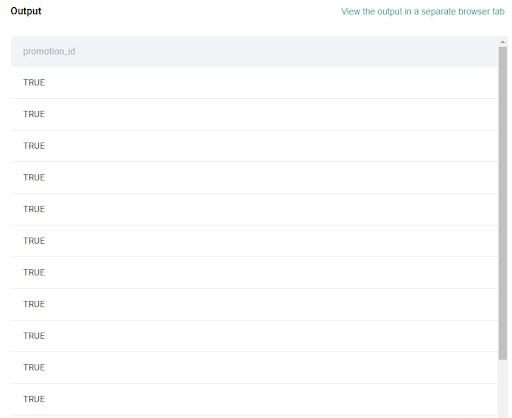
3. Split the merged table into valid and invalid promotion sales
Let’s now use this table to split up the merged table we had created earlier into valid and invalid promotion sales. We can split the merged table by the column ‘valid_promotion’ as shown below:
valid_promotion = merged[merged.valid_promotion]
invalid_promotion = merged[~merged.valid_promotion]
Valid promotion dataset is illustrated below:

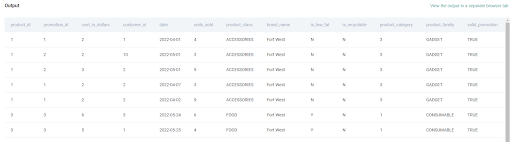
And the invalid promotions dataset is as below:


4. For each subset, compute the total units sold per product family
Now that we have segregated the merged table into valid and invalid promotion datasets, we can perform aggregation on these datasets to calculate the sum of units sold for the sales made in each of these datasets. We will use the groupby() function to get the total units sold at the product family level.
Let’s start with the valid promotions.
valid_promotion.groupby('product_family')['units_sold'].sum()
The output is a column of total units sold under a valid promotion. Let’s convert this into a dataframe using the to_frame() function that allows us to specify the column name directly in this line. Only append the previous code with the to_frame() function.
valid_promotion.groupby('product_family')['units_sold'].sum().to_frame('valid_solds')The output looks like this:

It does not make a reference to the product family that the sales are made on. It is being stored as an index. So, let us reset the index so that the product_family column will become available again. Append reset_index() function to the code above:
valid_promotion.groupby('product_family')['units_sold'].sum().to_frame('valid_solds').reset_index()Now the output displays the respective product family as well:
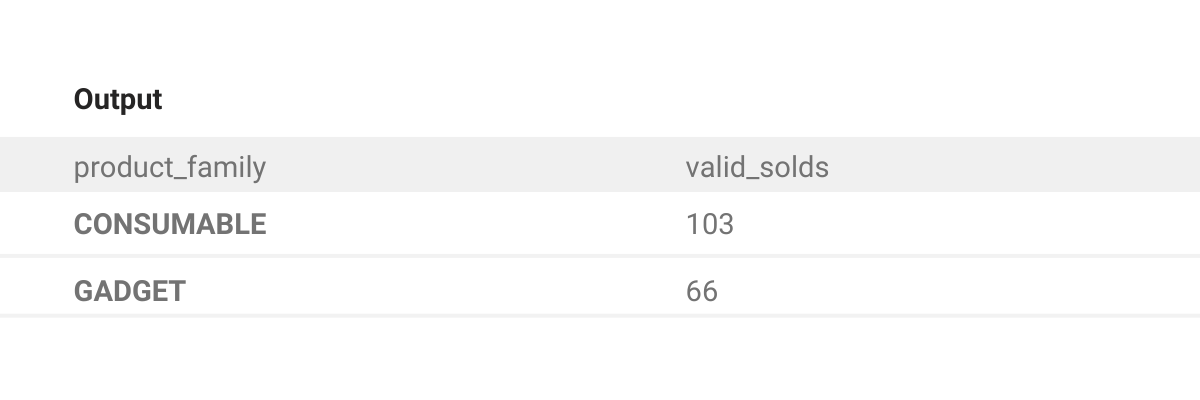
To differentiate between the valid and invalid promotions, let’s save the above line as results_valid and repeat the same steps for the invalid_promotion table.
results_valid = valid_promotion.groupby('product_family')['units_sold'].sum().to_frame('valid_solds').reset_index()
invalid_promotion = merged[~merged.valid_promotion]
Note that we have already typed out the code for invalid_promotion.
result_invalid = invalid_promotion.groupby('product_family')['units_sold'].sum().to_frame('invalid_solds').reset_index()The results_invalid table looks like this:
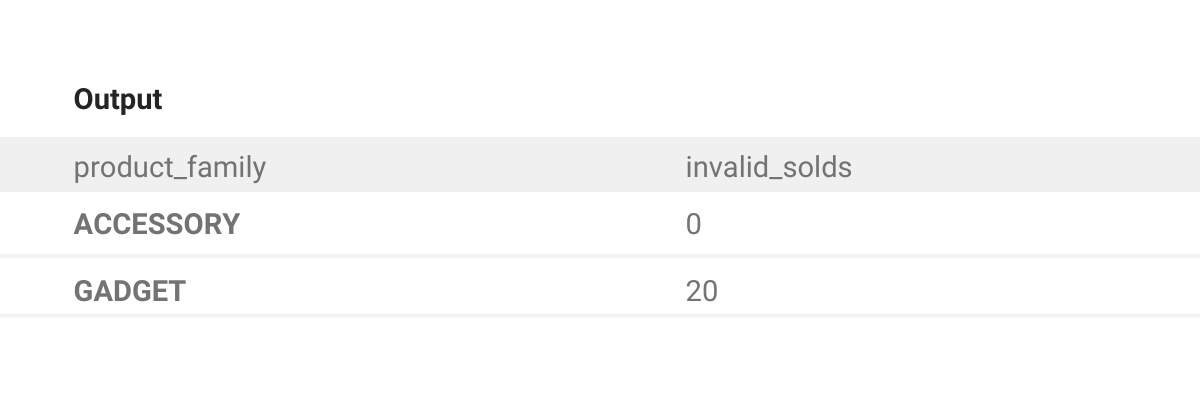
5. Merge the results for the valid and invalid promotions
Now, it is time to merge the two tables: results_valid and results_invalid. Basically, our objective is to make our calculations down the line easier. The main table will contain the product family, the total units sold under valid promotion as well as the total units sold under invalid promotion sales.
result = results_valid.merge(result_invalid, how='outer', on='product_family')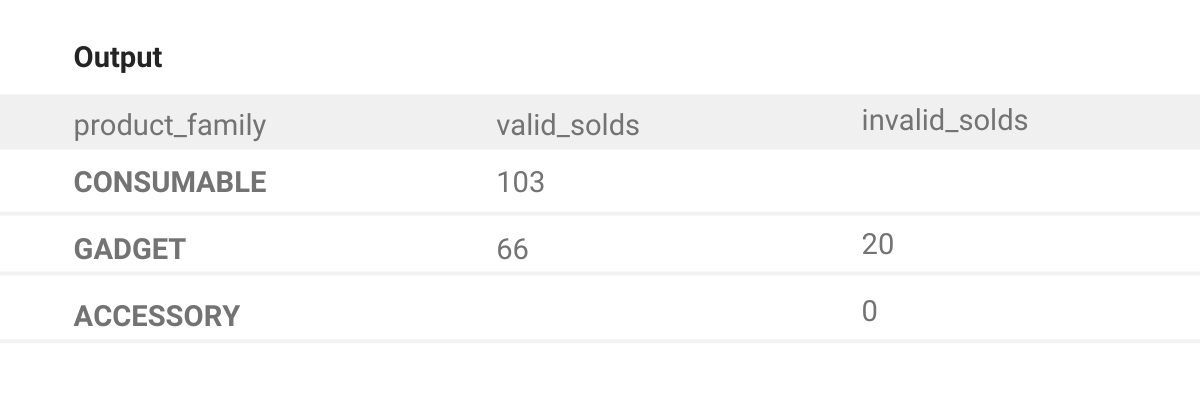
Let’s take a step back and consider the edge case scenario that we had identified earlier in Step 1, wherein a product family does not have any sales on a valid promotion.
Now that it comes up, there could be a scenario wherein all the sales are made under promotion which creates a missing value when we try to merge them. These scenarios, once made apparent, can be easily solved with the use of the fillna() function. All we need to do is fill the null values with zeroes.
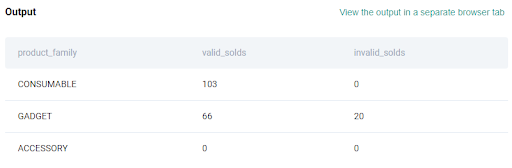
6. Fill null values with zeroes
Let’s append the previous line of code with the fillna() function as shown below:
result = result_valid.merge(results_invalid, how='outer', on='product_family').fillna(0)The output table is cleaner and will make our further calculations a cakewalk.

7. Calculate the total sales
Let us create new columns to store the value of total sales and the percentage of sales under valid promotions.
Firstly, let’s calculate the total sales, which but a sum of the valid_solds and invalid_solds.
result['total'] = result['valid_solds'] + result['invalid_solds']The output looks as shown below:

8. Calculate the percentage of units sold under promotion
The last piece of computation we need to perform is to capture the percentage of units sold under a valid promotion. We can calculate the same using the formula applied in the code below:
result['valid_solds_percentage'] = result['valid_solds'] / result['total'] * 100
The output of this line is as shown below:

9. Display the relevant columns, replacing any na’s with 0s
Lastly, let us select the required columns for our output: product_family, total, valid_solds_percentage, and add a final touch by replacing any na’s with zeroes.
Before displaying the results, let’s be mindful of the edge case scenarios where product families may have no sales i.e., the total units sold will be zero. Subsequently, the total units sold under a promotion would also be zero. You will be thrown an error when zero is divided by zero. We are covering this edge case by replacing any na’s with zeros.
Select the necessary columns as shown below:
result[['product_family', 'total','valid_solds_percentage']].fillna(0)
To get the complete picture of the solution, here is the complete solution:
import pandas as pd
merged = facebook_sales.merge(facebook_products, how="outer", on="product_id")
merged['valid_promotion'] = merged.promotion_id.map(lambda x: \
not pd.isna(x) and x \
in facebook_sales_promotions.promotion_id.unique())
valid_promotion = merged[merged.valid_promotion]
invalid_promotion = merged[~merged.valid_promotion]
results_valid = valid_promotion.groupby('product_family')['units_sold'].sum().to_frame('valid_solds').reset_index()
result_invalid = invalid_promotion.groupby('product_family')['units_sold'].sum().to_frame('invalid_solds').reset_index()
result = results_valid.merge(result_invalid, how='outer', on='product_family').fillna(0)
result['total'] = result['valid_solds'] + result['invalid_solds']
result['valid_solds_percentage'] = result['valid_solds'] / result['total'] * 100
result[['product_family', 'total','valid_solds_percentage']].fillna(0)
Now let us run the complete code to get the expected result as shown below.
If you dive a little further into the result table, we can see that there is no sale for the product family ‘Accessory’. Had we not handled the edge case, we would have been thrown an error during our calculations. You can see now how paramount it is to anticipate this at various points in our solution.
Conclusion
Despite the difficulty level of this Facebook python interview question, it was not as complicated as we would’ve expected. We hope you learned something about JOINs, data transformation, and aggregations.
Practice is the only way to mastery. Keep practicing from our Python Coding Interview Questions article.
Share


