Facebook Data Scientist Interview Guide


Categories:
 Written by:
Written by:Nathan Rosidi
We bring you a detailed analysis of what you should expect when you land your data science interview with Facebook that you always dreamed about.
Facebook is one of the largest public companies in the world and a global technological leader. Having said that, it’s no surprise that Facebook is a leader in data science and that it attracts the some of the most skillful data scientists in the world. According to their website “data scientists at Facebook conduct large-scale, global, quantitative research to gain deeper insights into how people interact with each other and the world around them.”
Being a leading technological giant and one of the FAANG companies, it is no wonder that Facebook puts data science at the core of its activities. All those pictures, videos, messages, likes, comments and many more activities we do by using Facebook are constantly stored and analyzed in order to improve the Facebook product (and all its affiliates) and keep the social media market dominance the company has enjoyed over the past decade.
Considering the sheer amount of data that gets collected, along with Facebook’s dominance and emphasis they put on data science, we have decided to do an analysis and come up with a guide on how the data science interview process looks like in there. With almost 200 real-live interview questions we collected on Facebook, we bring you a detailed breakdown on what you should expect when you land that interview with Facebook that you always dreamed about.
Description and Methodology of the Analysis
The goal of this article is to analyze various categories of questions being asked in Facebook data science interviews. Furthermore, this article will analyze the most prominent technical concepts that appear in these questions, in order to aid the reader (through examples) in understanding the background and approach for a lot of the questions from our database.
Earlier in our blog, we have published an article with the analysis of more than 900 questions collected from 80 different companies over the past 4 years. In that analysis, Facebook has been the most dominant company in terms of questions asked, as well as one of the leading organizations that puts high emphasis on coding questions.
We have managed to gather a total of 193 real-life Facebook data scientist interview questions over the past 4 years, from sources such as Glassdoor, Reddit, Blind App and Indeed. Below is the breakdown of questions, as categorized by our team:

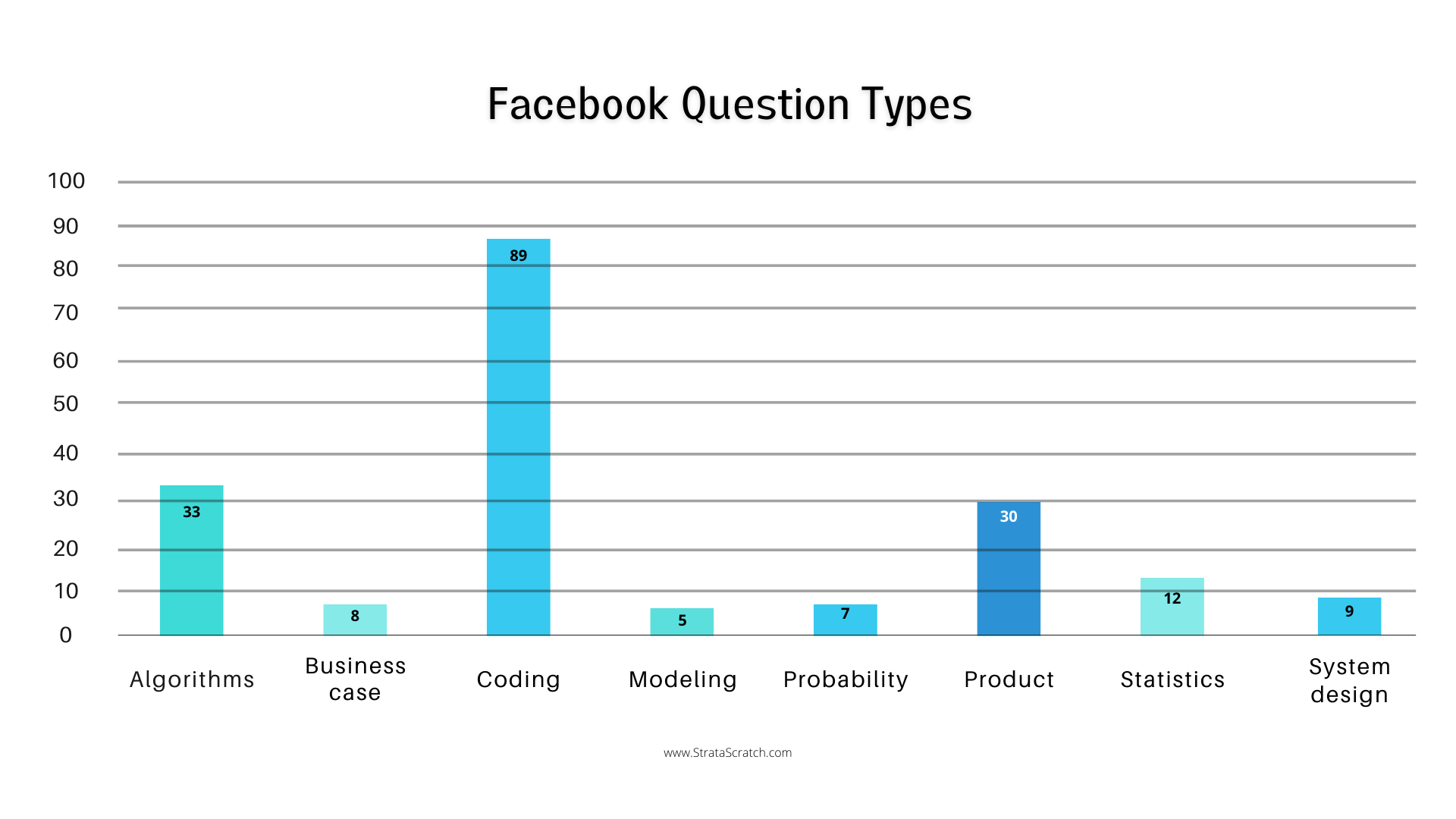
The question type data in our research has been produced by sectioning questions into pre-determined categories. These categories have been produced by an expert analysis of the interview experience description taken from our sources. When it comes to Facebook, our team has identified eight different categories of questions being asked. These are: algorithms, business case, coding, modeling, probability, product, statistics and system design. We will go into more detail explaining these categories further in the article.
Data Science Interviews at Facebook
Here we will cover our categorization method in more detail, along with the explanation on how the categories are selected and structured. Furthermore, we will analyze all the questions and see which categories are more prevalent in the Facebook data science interview process. Finally, we will go through real-life examples of questions being asked in Facebook interviews, for each of the categories. This should help you get a general sense of what to expect in Facebook interviews, as well as give you specific knowledge on some of the questions you might get asked.
Facebook Question Type Breakdown
Let’s take a look at all of the Facebook interview questions that we have gathered for the purpose of this article:
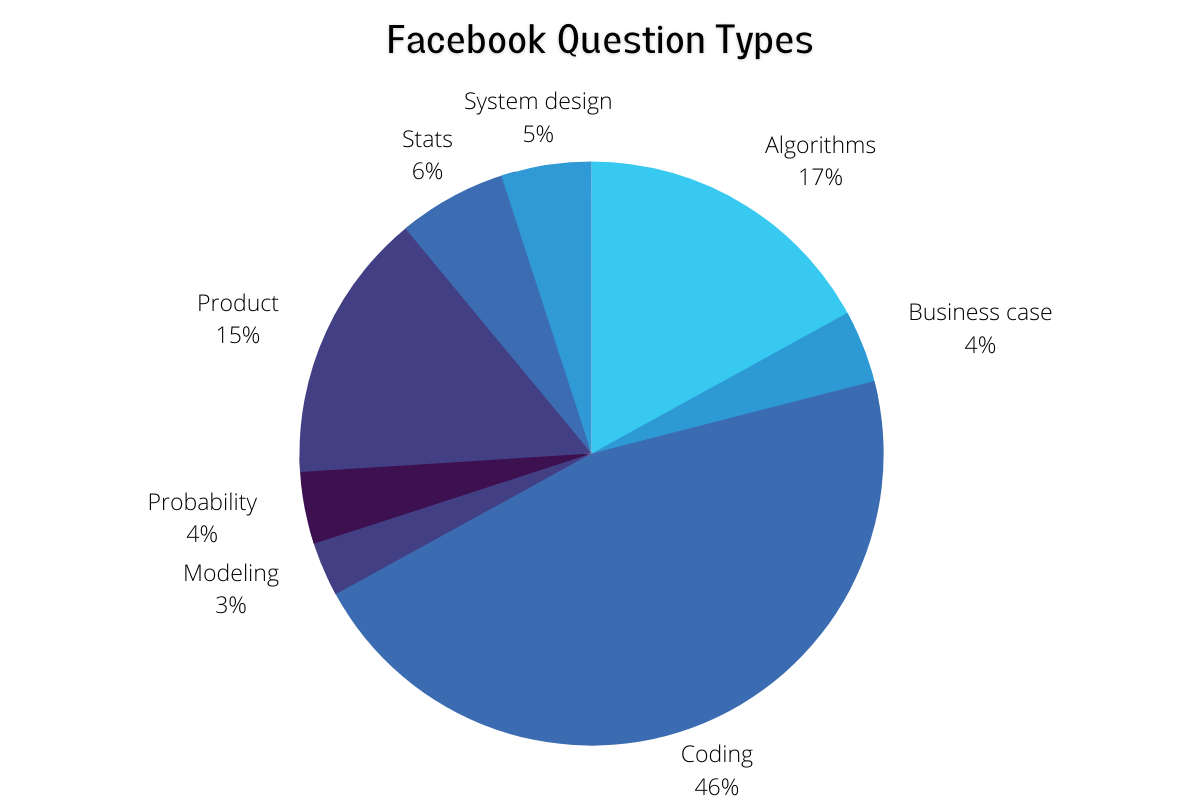
As we have mentioned before, and as we can see on the graph, Facebook puts a lot of emphasis on data science coding interview questions; this single category makes up almost half (46%) of all the questions in our database. Since this is the case, we will put more emphasis on questions from this category in our article, in order to help you better prepare for your interview at Facebook. Two other prominent categories are algorithms and product, making up 17% and 15% of all questions respectively. Statistics makes up 6% of all the questions in our database, and this is the final category on the list with more than 10 examples, as you could see on the graph in the section above. System design makes up 5%, business case and probability make up 4% each, while modeling is the least dominant category with 3% of such questions being asked in Facebook data science interviews.
Coding
Under our categorization criteria, we have identified coding questions to be all types of questions which involve analysis and data manipulation through code. This manipulation through code is usually done using some of the most popular languages in data science such as SQL (most common), Python and R.
An example of a coding question specific to Facebook would be:
“Find whether the number of senior workers (i.e., more experienced) at Facebook is higher than its number of USA based employees. If the number of seniors is higher then output as 'More seniors'. Otherwise, output as 'More USA-based'.”

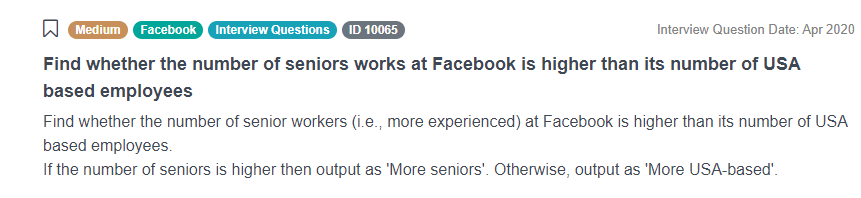
We will discuss the possible solution to this question in Postgres, so you can get more familiarized with approaching a similar issue in your interview:
- First, use two inner queries to find the number of seniors and the number of USA based employees;
- Then, use the formula SUM(CASE WHEN ... THEN 1 ELSE 0 END) to count the number of seniors;
- After that, use the function COUNT() to count the USA based employees. Consider USA based employees have the value of 'USA' for the location column;
- Use the WHERE clause to apply conditions;
- Then, use LEFT JOIN to combine the results of both queries on TRUE;
- Finally, use the formula CASE WHEN ... THEN ... ELSE ... END to find the final output.
Here is the entire solution in Postgres, from our platform:
SELECT
CASE
WHEN n_seniors > n_usa_based
THEN 'More seniors'
ELSE 'More USA-based'
END AS winner
FROM
(SELECT
SUM(CASE WHEN is_senior THEN 1 ELSE 0 END) AS n_seniors
FROM
facebook_employees) seniors
LEFT JOIN
(SELECT
COUNT(*) AS n_usa_based
FROM
facebook_employees
WHERE
location = 'USA'
) us_based
ON TRUESince coding is the most prevalent category of all interview questions, let’s look at a few more examples related to coding. One such example would be:
“Calculate the total revenue from each customer in March 2019. Revenue for each order is calculated by multiplying the order_quantity with the order_cost. Output the revenue along with the customer id and sort the results based on the revenue in descending order.”

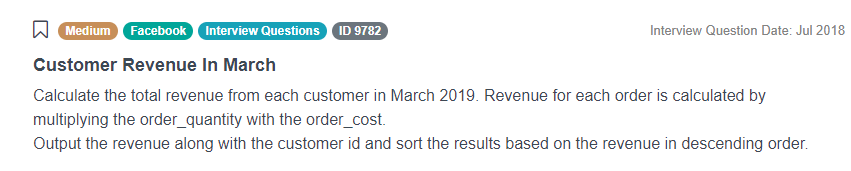
Possible solution can be found on our platform.
Final example from this category:
“Find the popularity percentage for each user on Facebook. The popularity percentage is defined as the total number of friends the user has divided by the total number of users on the platform, then converted into a percentage by multiplying by 100. Output each user along with their popularity percentage. Order records in ascending order by user id. The 'user1' and 'user2' column are pairs of friends.”

Solution to the popularity percentage question by Facebook.
Coding questions are being asked on Facebook data science interviews in order to test the candidate’s problem-solving skills, technical knowledge of the programming language in use and creativity; all of which you would most likely need on a daily basis at Facebook. As we have seen in the previous section, the importance of knowing how to answer coding questions can never be overstated, since they make up almost half of all interview questions being asked.
Algorithms
Questions on algorithms are categorized as all questions that require solving a mathematical problem, mostly through code, by using one of the programming languages mentioned above. These questions involve a step-by-step process usually requiring adjustment or computation to produce an answer. You might be asked either to explain your answer or to actually implement the code.
An example of an algorithmic question would be to find a square root of a number using Python or R. These questions are important to test the basic knowledge of problem-solving and data manipulation which can be implemented for complex problems at work. As we can see in the graph above, questions related to algorithms make up 17% of all questions being asked in Facebook interviews.
Product
Interview questions related to product have been categorized as all questions which require evaluation of a product/service through data. These types of questions are asked to test whether the candidate could implement data science principles on real-life, day-to-day problems that Facebook experiences as a company. Here’s an example of a product question, specific to Facebook:
“If 70% of Facebook users on iOS use Instagram, but only 35% of Facebook users on Android use Instagram, how would you investigate the discrepancy?”


As we have seen in the graph above, product questions make up 15% of all questions being asked in Facebook interview. Since Facebook’s product(s) are very complex and rich in data, it makes perfect sense why this is the case. Being able to answer product-related questions is extremely important, as it shows your knowledge of Facebook’s offerings and how easy you would be able to adapt to daily tasks at the company.
Statistics
Statistics interview questions have been categorized as all questions which require knowledge of statistical theory and related concepts. These questions are asked in order to test the interviewee’s knowledge on founding theoretical principles which are used in data science tasks.
Here is an example of a question categorized under statistics, from our platform:
“What is the expectation of the variance?”


One way to answer this question would be something like this:
- Let X be a random variable;
- We know that E(a) = a, if a is a constant
- We also know that E(E(X)) = E(X), because E(X) is a constant.
- Since Var(X) = E(X^2) - E(X)^2, then:
E(Var(X)) \\= E(E(X^2) - E(X)^2) \\= E(E(X^2)) - E(E(X)^2) \\= E(X^2) - E(X)^2 \\= Var(X)
Another statistics-related question would be:
“In Mexico, if you take the mean and the median age, which one will be higher and why?”


Questions related to statistics are quite significant since being able to understand the theoretical and mathematical background of analyses is something every company is looking for. This demonstrates that the candidate has more in-depth knowledge of the problems at hand and not just the hands-on experience of resolving issues.
System Design
System design questions have been categorized as all questions related to designing technology systems. These questions are asked in order to analyze your individual process in solving problems and creating systems to benefit customers/clients. An example of a system design question from our platform would be:
“Given data on Facebook members friending/defriending each other on Facebook, find out whether a given pair of members are currently friends.”


Knowing system design can be quite important for a data scientist; even if your role is not to design a system, you will most likely play a role in an established system and need to know how it works in order to perform your daily responsibilities.
Probability
Our categorization of probability questions is all questions which require theoretical knowledge only on probability theory and concepts. Interviewers ask probability-related questions in order to get an understanding of your knowledge on the methods and usage of probability to complete the complex data tasks which are usually performed in the workplace.
An example of a probability question would be:
“What is the probability of pulling a different color or shape card from a shuttled deck of 52 cards?”


Business Case
Business case questions have been categorized as questions involving case studies as well as generic questions related to the business that would test some data science skills. They make up only 4% of all questions being asked in Facebook interviews; nevertheless, they can be quite important as you could be asked a business case specifically related to the operations of the company. If you are able to answer it, you could end up resolving a current problem that Facebook is facing even before being hired.
Here is an example of a business case question, specific to Facebook:
“How do you map nicknames used in Facebook users’ names (Pete, Andy, Nick, Rob, etc) to real names?”


The significance of knowing how to answer these questions can be enormous as most interviewers would like the candidates to know how to apply data science principles to solve Facebook’s specific problems before hiring them.
Modeling
Interview questions under the modeling category are all questions related to regressions and machine learning. Even though modeling questions make up the lowest percentage of all questions being asked (3%), they can be of crucial importance depending on your role. In fact, for some of the roles at Facebook, constructing models can make up the majority of your tasks.
An example of a modeling question from our platform would be:
“How would you test whether having more friends now increases the probability that a Facebook member is still an active user after 6 months?”


Technical Concepts Tested in Facebook Data Science Interviews
In this section, we will talk about some of the most common technical concepts tested in Facebook data science interviews. As we have seen from our analysis, Facebook puts a heavy emphasis on coding questions, along with questions on algorithms which usually have a coding component to them. Taking that into consideration, it is no wonder that the most prominent technical concepts come from these areas.
Joins
The most common technical concept tested in Facebook data science interviews is the usage of joins (in SQL) to merge tables and columns in order to perform further analysis on the data. An example of this type of question from our platform is below:
“Facebook sends SMS texts when users attempt to 2FA (2-factor authenticate) into the platform to log in. In order to successfully 2FA they must confirm they received the SMS text message. Confirmation texts are only valid on the date they were sent. Unfortunately, there was an ETL problem with the database where friend requests and invalid confirmation records were inserted into the logs, which are stored in the 'fb_sms_sends' table. These message types should not be in the table. Fortunately, the 'fb_confirmers' table contains valid confirmation records so you can use this table to identify SMS text messages that were confirmed by the user. Calculate the percentage of confirmed SMS texts for August 4, 2020.”


To answer this question, you would need to filter out the invalid confirmation and friend request records in the 'fb_sms_sends' table. You would JOIN the tables using both the phone number and date keys; a LEFT JOIN is required to preserve the count of the total number of messages sent. Since you are working with integers, you would need to convert the data type to a float or a decimal in the SELECT clause. Detailed answer (with code) can be found on our platform.
CASE Statements
Another important technical concept frequently being brought up in Facebook data science interviews is the usage of CASE statements (in conjunction with all its variations). For example, you could be asked a question like this:
“Find how the number of `likes` are increasing by building a `like` score based on `like` propensities. A `like` propensity is defined as the probability of giving a like amongst all reactions, per friend (i.e., number of likes / number of all reactions). Output the total propensity alongside the corresponding date and poster. Sort the result based on the liking score in descending order. In `facebook_reactions` table `poster` is user who posted a content, `friend` is a user who saw the content and reacted. The `facebook_friends` table stores pairs of connected friends.”


The answer to this Facebook question (using a CASE WHEN statement).
Find more recent Facebook Data Scientist interview questions
UNION ALL Operator
The last prevalent technical concept from Facebook data science interviews that we will cover in this article is the UNION ALL operator. This concept is mostly used to combine certain data sets in order to perform analysis on all of them at the same time. An example of such a question:
“Find the date with the highest total energy consumption from the Facebook data centers. Output the date along with the total energy consumption across all data centers.”


The answer to this question can be found on our platform.
Check out our previous post on Facebook Data Scientist Position Guide to find out what it means to be a data scientist at Facebook.
Conclusion
The thorough analysis of Facebook’s data science interview questions in this article has been conducted with the intent of aiding you in becoming a member of the Facebook data science team. We have managed to categorize all 193 questions into 8 different sections and have conducted a detailed examination of each of the categories, along with the overall breakdown of questions themselves. The most tested technical concepts have been covered, along with specific examples of data science interview questions in order to get a better understanding of what the interview process would look like. Special emphasis has been put on coding questions, as they make up almost half of all the questions being asked in Facebook interviews.
As Facebook keeps growing and maintains its social media market dominance, it is understandable why the company constantly expands its data science teams around the world, and why they attract more applications with every job posting. We hope this article has proven to be a valuable resource in your journey to becoming a data scientist at Facebook and we wish you all the luck with working there in the future.
Share


