Discussing Trade-Offs in Your Code During a Data Science Interview

Categories:
 Written by:
Written by:Nathan Rosidi
This data science interview tip is to always communicate trade-offs in your logic as you are coding up your solution.
As a data scientist, there are multiple ways to handle and manipulate data and oftentimes there are no right or wrong answers, just solutions with limitations and considerations. As a data scientist, your job is to be able to communicate those limitations and those trade-offs to your stakeholders so that the correct decision can be made using your insights.
Understanding that there are pros and cons and trade-offs to every solution as you're designing it, and to be able to communicate what those tradeoffs actually mean to the solution and to the decision that needs to be made makes you a very successful data scientist. Your job as a data scientist is not only to be able to design and code up solutions but it's really to be able to guide your stakeholders to making the correct recommendation.
Apply this tip of communicating trade-offs to a real data science interview question
This data science interview question comes from Facebook:
Also, find a link below to follow along with me. This link will take you to the StrataScratch platform:
https://platform.stratascratch.com/coding/10285-acceptance-rate-by-date?python=
In the above image, you can see the table schema and data that we'll be playing with as well as an editor to write in either SQL or Python.
The question is:
What is the overall friend acceptance rate by date?
Order by the latest friend request date to the earliest date

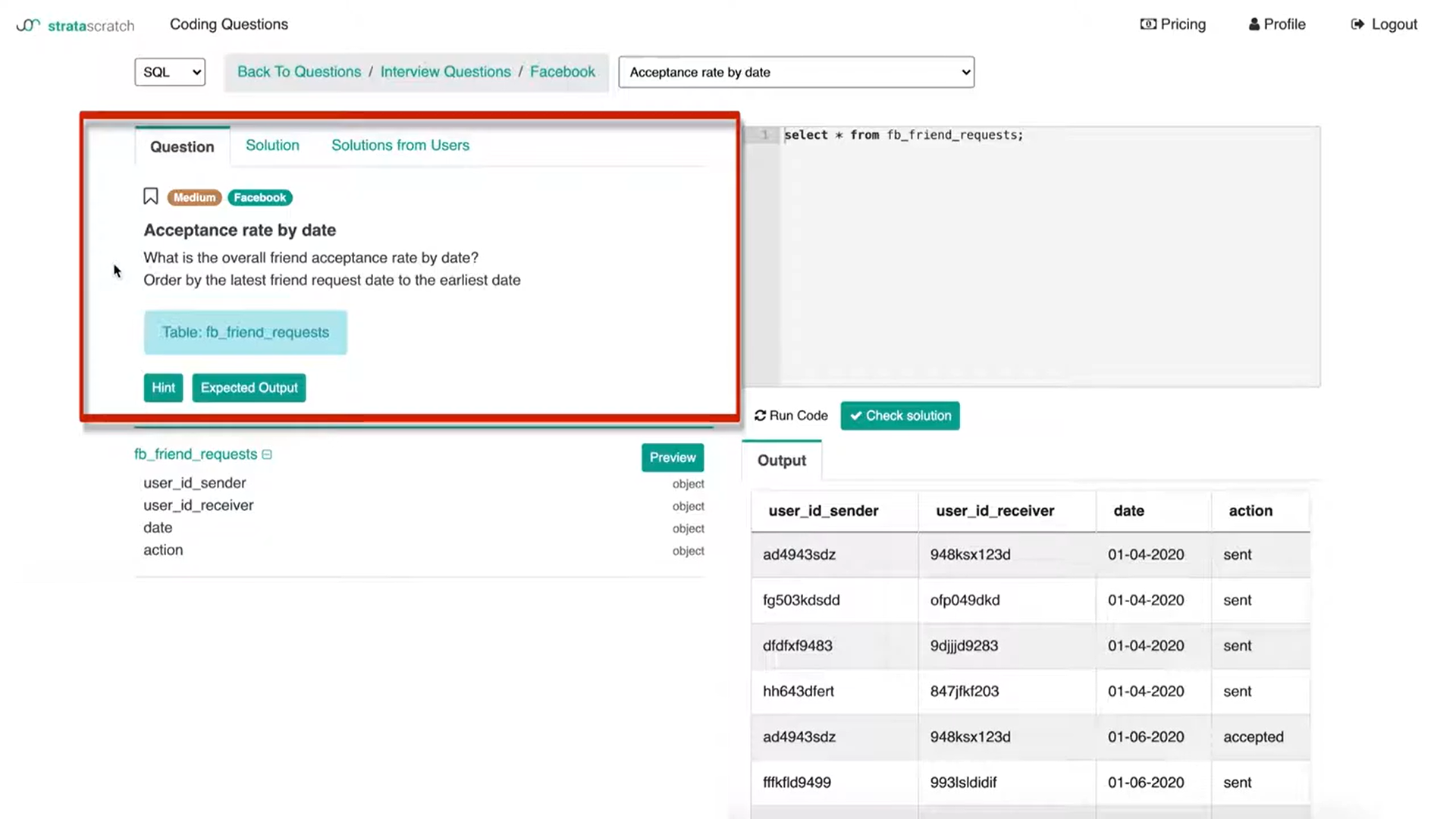
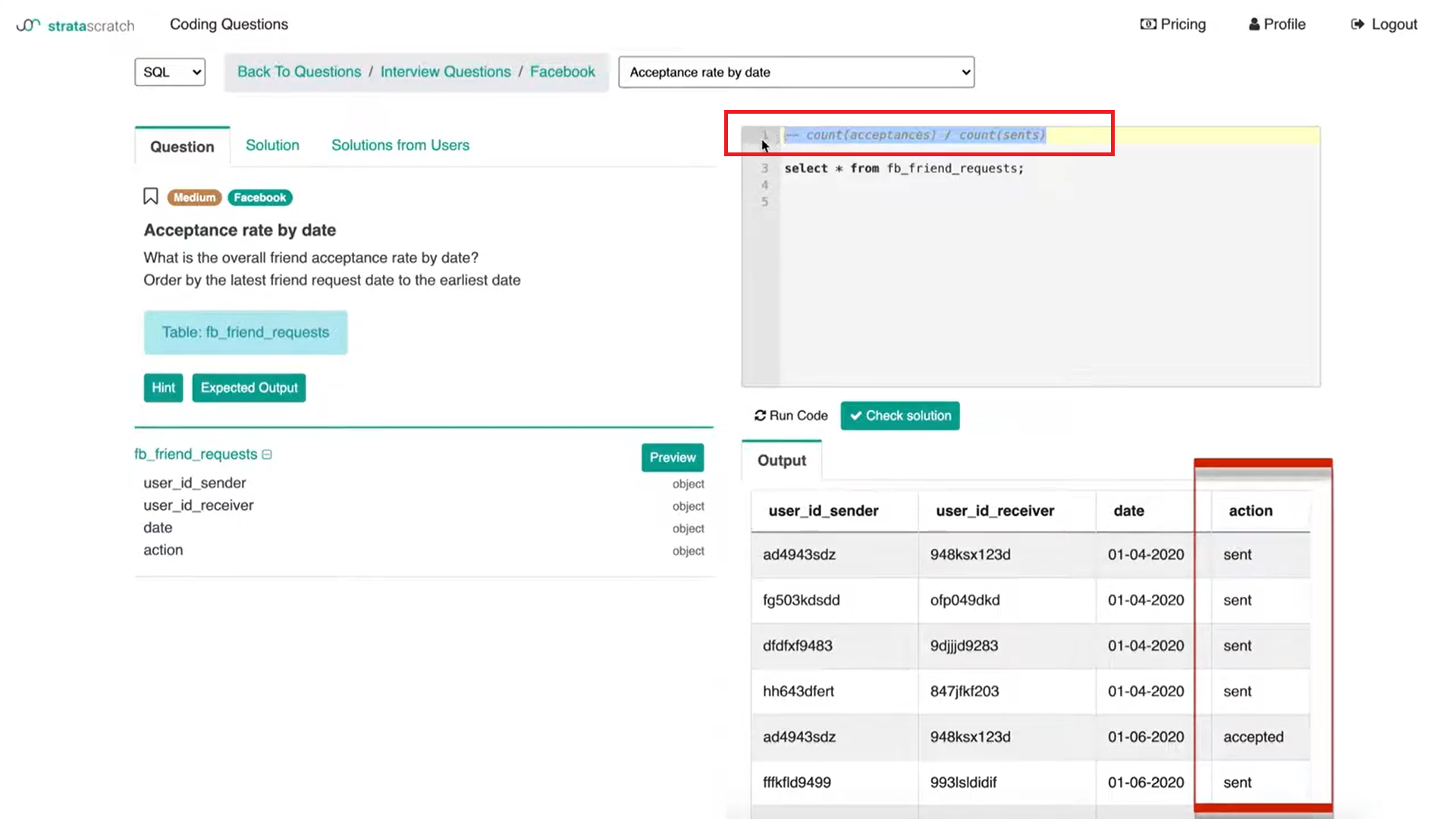
Then you are given the table with the user id of the sender and the receiver and a date field as well as an action column. If we press ‘Preview’, we get the preview of the table and the underlying data.
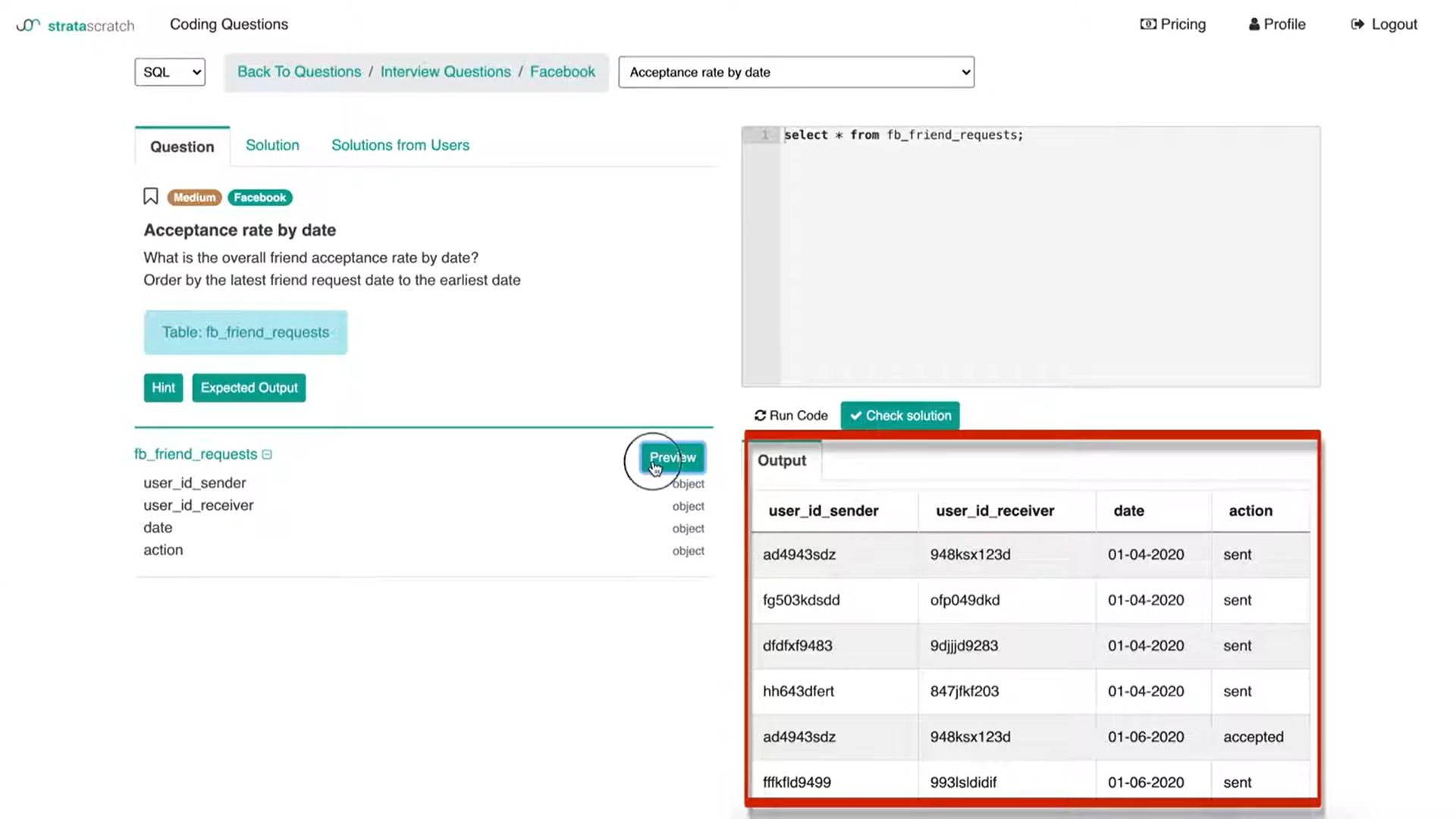
We have an understanding of not only the columns but then the data inside the table as well to be able to answer this Facebook data science interview question. I think this is somewhat of a straightforward question in terms of what we need to do to it.
What might make this a more valuable exercise is if you pause right here and try to code up the solution to this question and then come back when you're done. Then I'll take you through my approach to the solution and let's just match our solutions at the end.
When I take a look at the question again and then at the underlying data, this is actually a pretty simple question in terms of the code that I'm going to use to create the solution!
I know the metric that I'm going to be coding up will be a count of acceptances divided by a count of the number of sents.
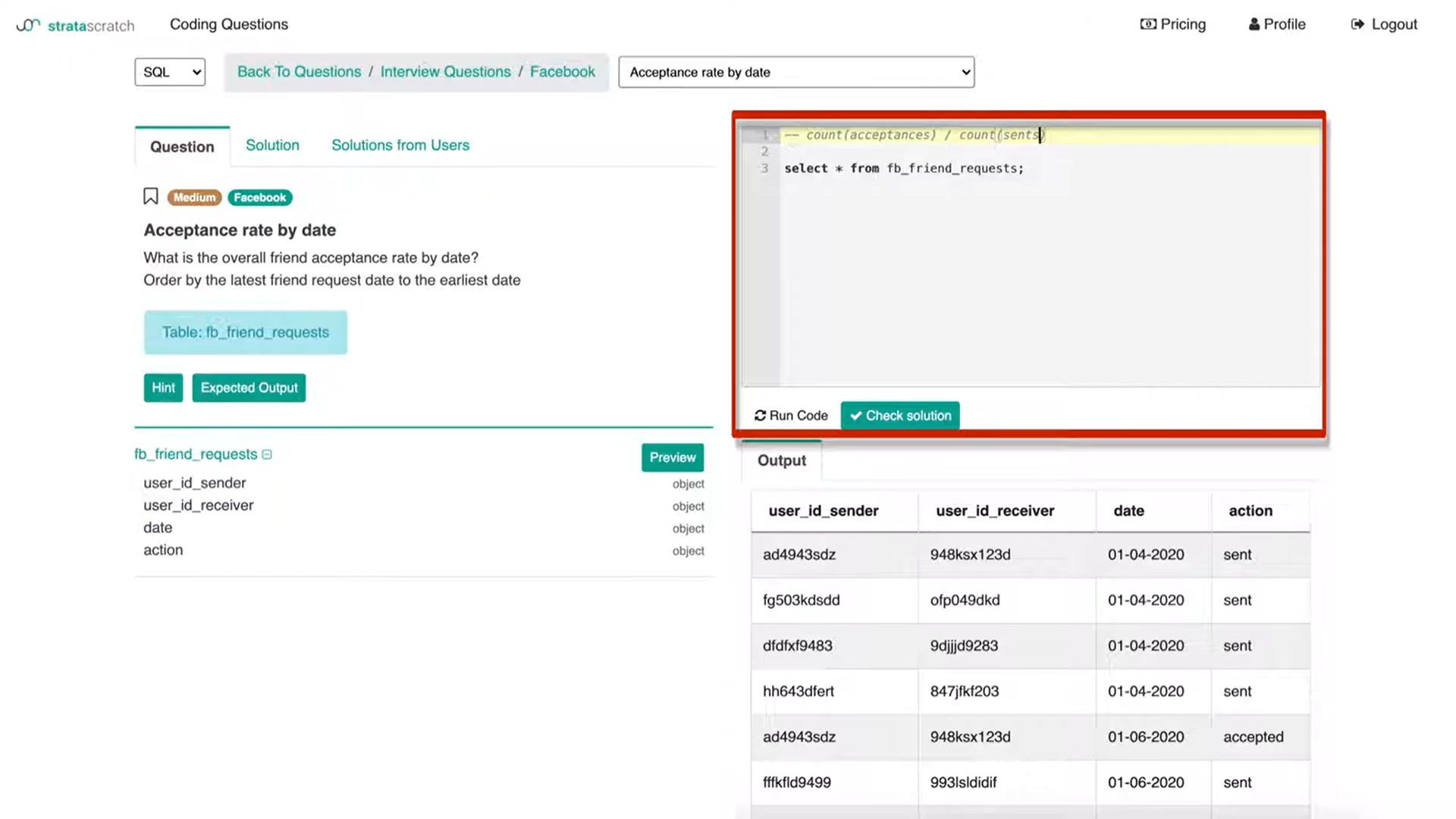
That's definitely going to be in the ‘select’ clause and then I'll work my way down to create two tables and then a ‘where’ clause where I'll add some logic.
The first test by the interviewer is actually a coding test. They just want to see whether or not you can code in either SQL or Python or whatever language you choose for the interview.
This is kind of unique that there's only one table. In an interview especially when they're trying to test your technical skills you're typically going to have multiple tables to merge or join together. But in this case, we actually don't have that.
The first thing in my head is there going to be a self join or a subquery needed in this solution. And I think the answer is yes! Because in the action column you have ‘sent’ and ‘accepted’ and we already know from the line at the top we want to count the number of ‘acceptances’ and the number of ‘sents’.
I can split this one table into two tables based off of sent and accepted in the action column.
Here's how we do that!
If you're following along with me here is how I am separating this table into two tables and joining it onto itself.

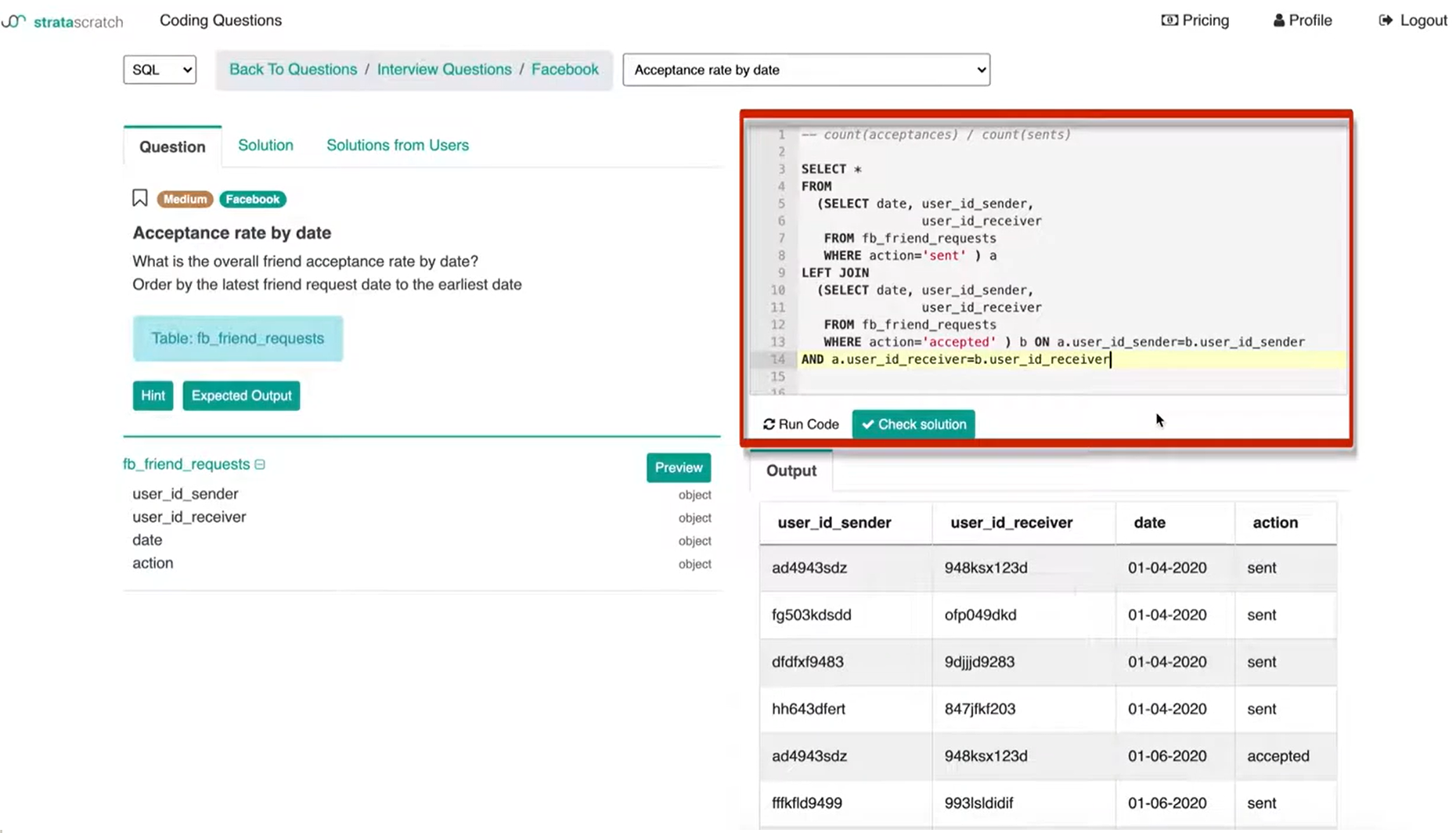
What I'm doing in this first sub query that I've aliased with ‘a’ is that I'm splitting this table by action. I have action sent and then I have action accepted in the left join in my second subquery. This makes sense because what I'm trying to do is split the number of ‘sents’ and then the number of ‘accepted’ because I want to get the count of ‘sents’ and ‘acceptances’. So, I need to really split them up between this table into two tables.
The reason why I'm using a left join is that the number of ‘sents’ should be greater than the number of ‘acceptances’. If I do a left join, I actually get to preserve that numbering or that count.
The interviewer is definitely interested in your technical ability to understand and code up the fact that this table needs to be split in two by ‘sent’ and ‘accepted’ and then rejoined together using a left join to preserve the row count.
If you run this code, it seems like it works. We get all of the columns we want.
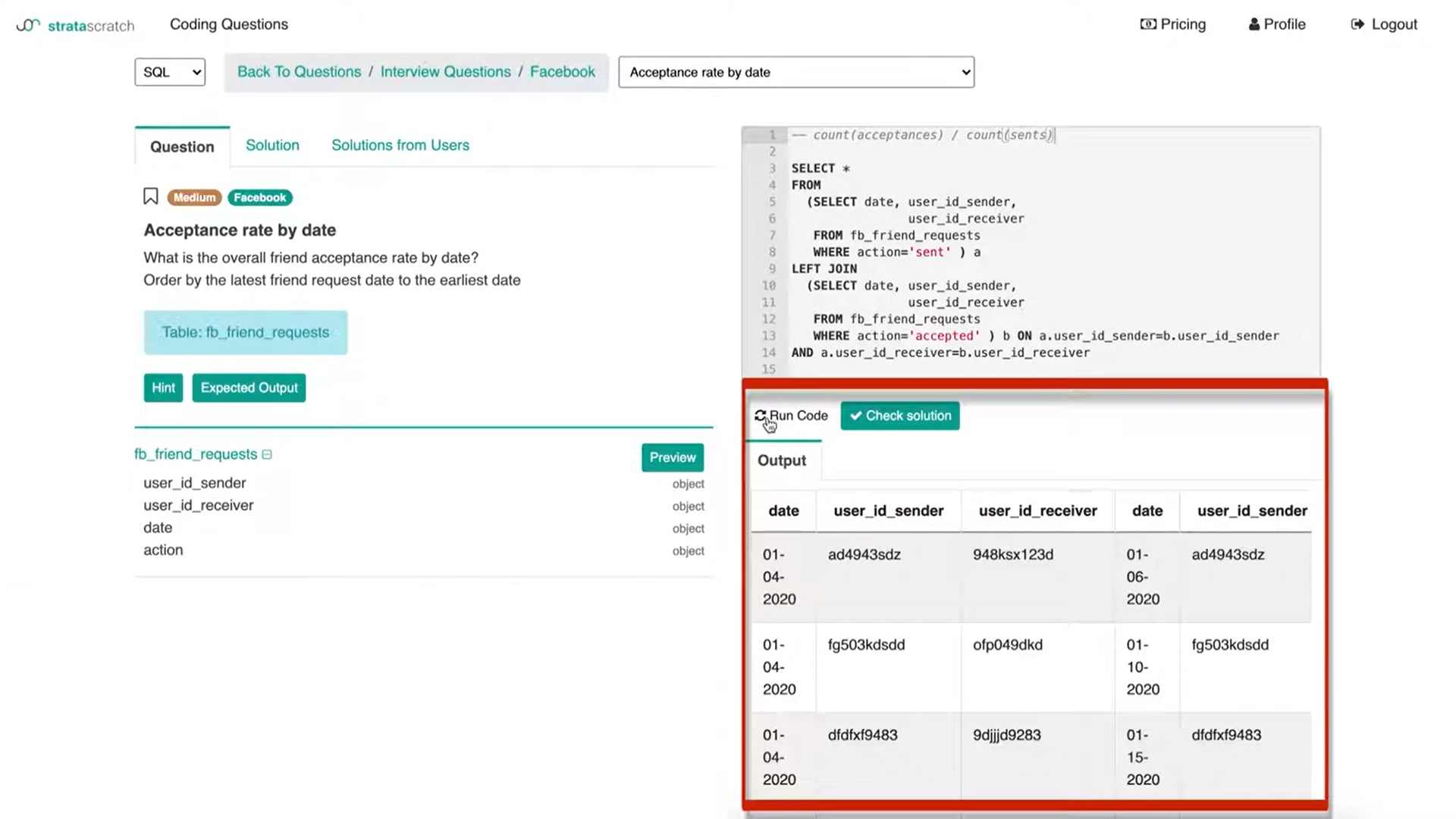
Then if we see in the bottom, there are a few empty rows from the left join and that's exactly what we are expecting.
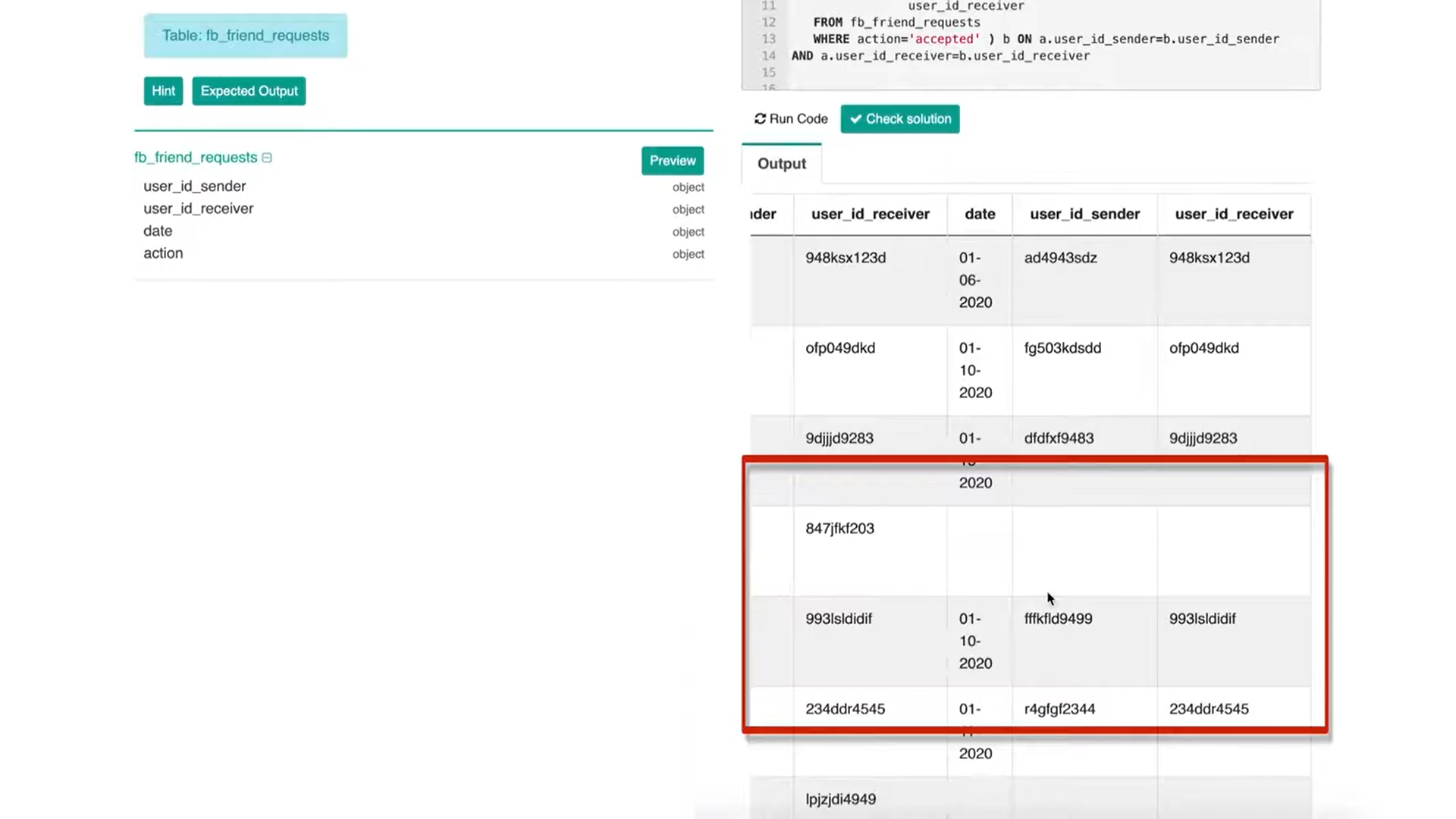
The next topic to consider is adding in the ‘date’ component to your solution because the question is asking for it.
What is the overall acceptance rate by date?
I can do this in one of two ways!
The first way is - in the ‘WHERE’ clause, I can pick a specific date and just basically filter out all of the data based on that specific date. If I do that I get the acceptance rate for a date that I choose versus putting a date or a date field in the outer portion of the SQL solution so that you get an acceptance rate for every date in this table. You can actually see the progression of acceptance rates by date.
These are essentially two ways to solve this problem and what I would do is ask the interviewer what they want.
Then the conversation about trade-offs begins!
If I put in a date field in the ‘WHERE’ clause, what I get is the acceptance rate for one date which could actually make the query run a little bit faster because you're limiting your solution set or the data that you need to come up with a solution. If you put the date in the outer part of the SQL query, that is going to take a little bit longer to run the query because you are calculating acceptance rates for every single date. If you have billions of rows this could take a while but you have the advantage of seeing the acceptance rate and how it actually progresses and changes by date for probably every single day.
What you could do to scale this up and make this into a production run is to make this a job or a SQL query that runs overnight or every night so that you get the acceptance rate for every day.
So, this is the discussion of trade-offs that you should be having with the interviewer because you are showing the interviewer that you understand the limitations and the pros and cons of every solution that you are coming up with because there are multiple ways to come up with solutions to this given question or problem.
The data topic that I want to bring up is what data to actually count.
I see essentially two trade-offs!
If I count friend requests that have been sent either today, yesterday or the day before, that really haven't had much time to mature. The other friend that gets the friend request may not have had enough time to actually see that notification or that email and actually accept that friend request.
If we count very recent data then the acceptance rate might be lower than actual. The opposite is what if it's a friend request that hasn't been accepted for over a year ago, do we actually want to count that? That depends on the use case; Am I running an experiment? Am I trying to test out a feature? If the answer is yes to either of them, you may not want to keep old data points.
Depending on the use case and what you're trying to do and the decision that you're trying to make, it really will affect and impact how you write the code and decide on what data you want to keep and throw away.
Let's say I talked to the interviewer and we decided to only keep data records that are older than 12 days from today. How would I implement that?
The way I implemented that was essentially just to put some logic in the ‘WHERE’ clause where I'm taking today's date and I'm going back 12 dates and I'm only then keeping data records that are older than 12 days from today.
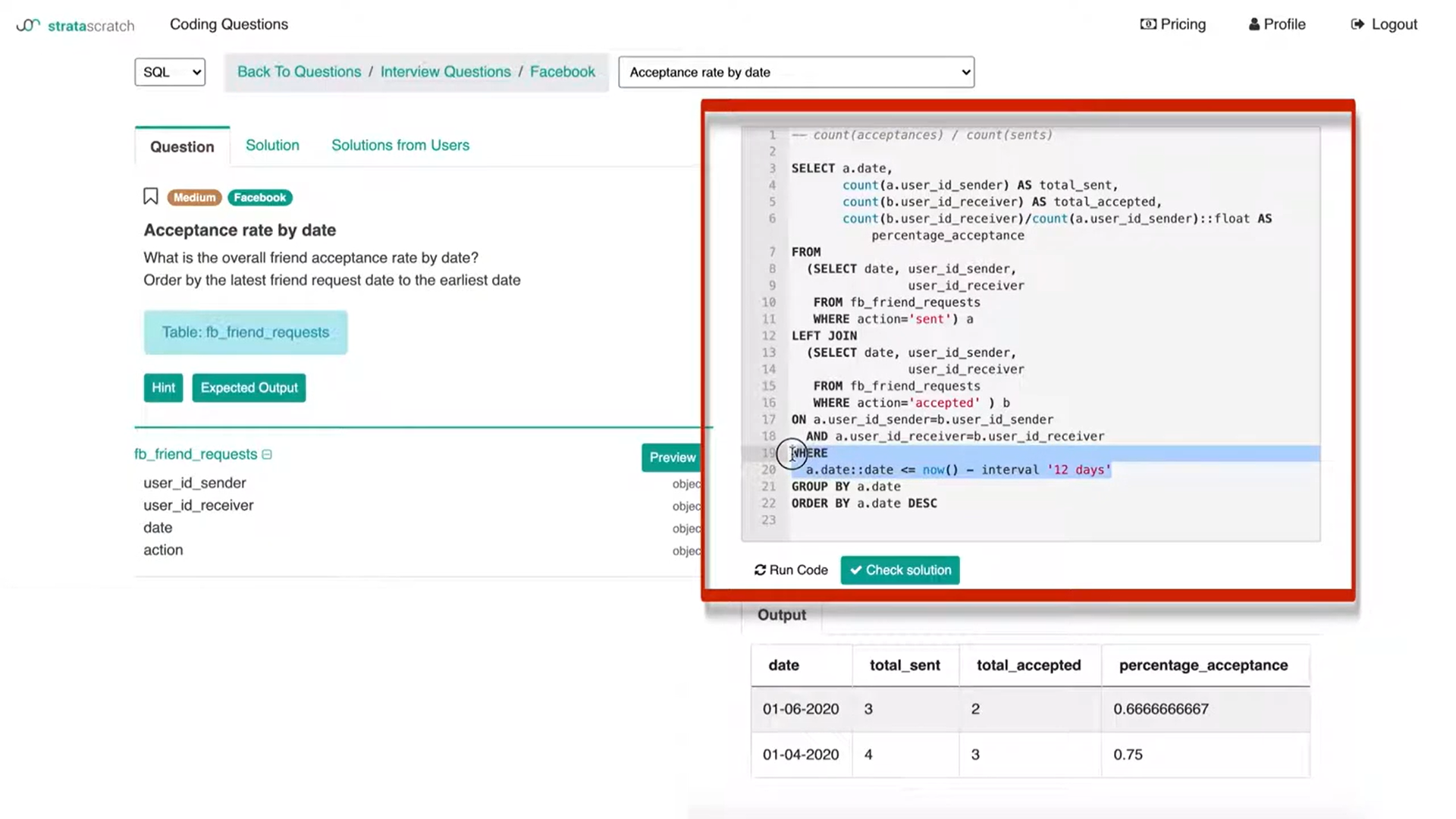
This is one way to do that. But what's important here is not that I was able to code this up because to the interviewer I already know how to code. So, adding just this logic statement is not a big deal but what's really important in the interview is to actually have a discussion about this.
With that conversation, I would say that this solution is done. The solution and then the conversation about trade-offs like how we want to actually count these users, whether or not we want to put the date field in the select clause or in the subqueries and whether or not to throw away or keep recent data, all of that is a discussion about trade-offs and a conversation about how your decision will impact the number and the solution that you're going to get at the end and how that might impact decision making.
Purpose Behind Communicating Trade-Offs
The purpose of communicating trade-offs is to show the interviewer that you have a deep understanding of what the solution actually means. If you write it one way you're going to get a different solution or answer and if you write it another way you're going to get another solution or answer.
The most important part as a data scientist is the ability to guide your stakeholder to make these decisions and then communicate the limitations and considerations of your code and what it means to the actual number that comes out and what it means to the output.
In your data science interviews, you should communicate any limitations and trade-offs to your solution as you're coding it up as this:
- allows you to understand if your interviewer wants you to code up your solution in any different way
- allows you to flex your skills on one understanding and showing the interviewer how you can manipulate data in different ways
- allows you to communicate your skills on communicating limitations and trade-offs to your solution and what that means to insights and recommendations that need to be made after you come up with a solution.
Share


