Data Cleaning 101: Avoid These 5 Traps in Your Data


Categories:
 Written by:
Written by:Nathan Rosidi
Data cleaning is a foundational skill in data science. Learn the five most common traps your data hides and how to recognize and handle them like a pro.
Not all data scientists are created equal – some are amazing at creating machine learning models, while others are great at creating visuals.
But one thing all – literally all – data scientists need to be good at is cleaning data. So how do you get good? You should start with not sucking at it first!
And you stop sucking when you stop ignoring these five mistakes in your data. Let’s first see what they are. At the end of the article, I'll propose one solution that can solve all five of these mistakes.
If you like hearing my voice while you read this article, here’s the video where I talk about these data-cleaning mistakes.
Mistake 1: Handling Missing Values
One thing you'll notice when you're cleaning data is that there are almost always missing values. Most people don't know why data is missing. A higher power at work? Data being lost in the laundry? It’s not up to you to find an answer. What you need to do is handle these missing values.
Not doing it can introduce bias and lead to crazy, inaccurate conclusions. There are many ways of handling missing data. These three are the most common:
- Removing rows or columns that have the missing data
- Imputing missing values using proxies like mean, median, or mode
- Using algorithms that can handle these missing values, e.g., random forest
Mistake 2: Handling Outliers
The opposite of missing values are outliers. It’s just a fancy word for data that makes no sense.

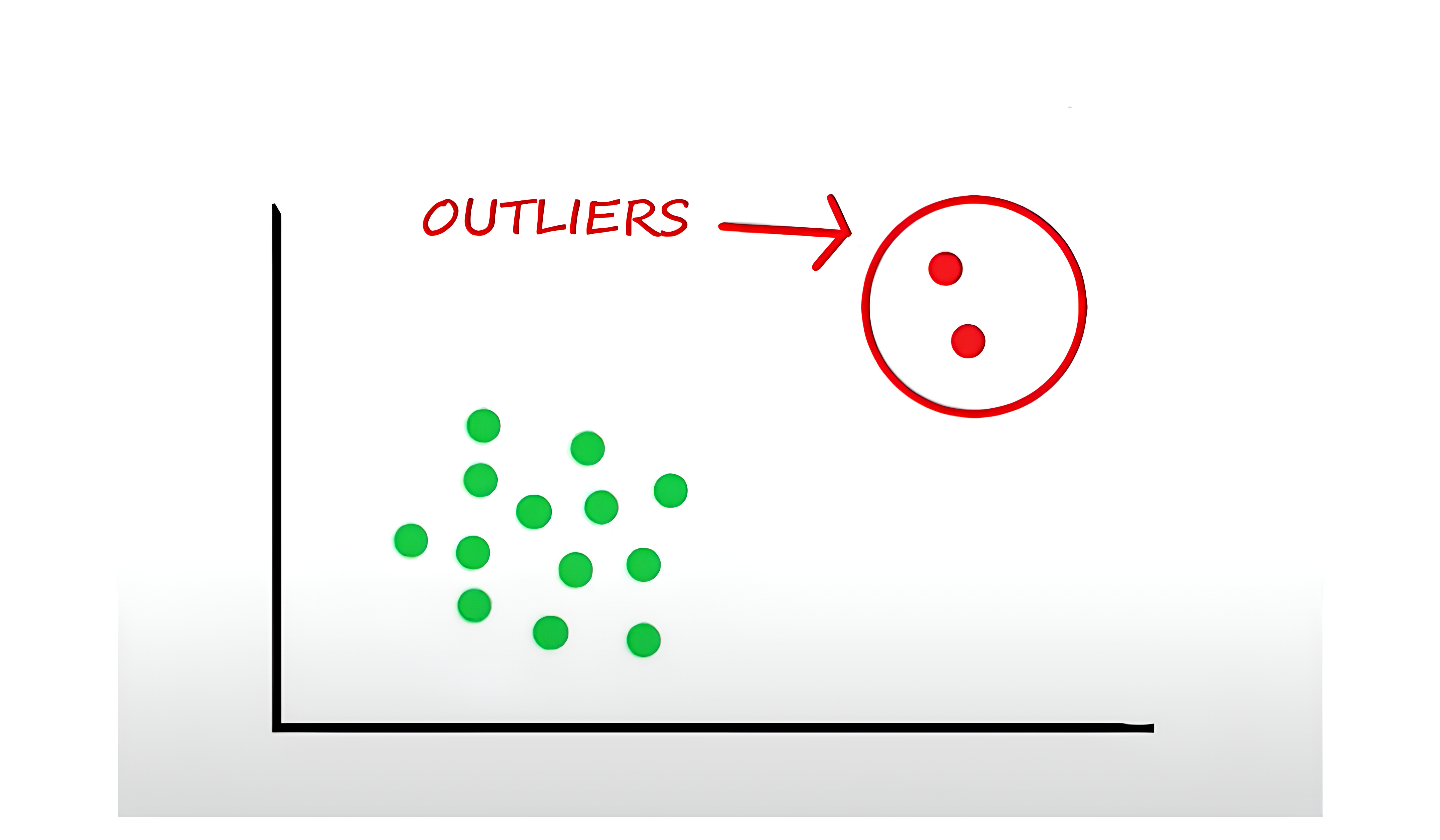
Not handling these outliers correctly can skew your view and your conclusions. But also, how do you know an outlier is an outlier? For example, a $2 million house might be an outlier. Unless you live in New York or San Francisco, that is. Then, $2 million is just the average price.
How do you, then, find outliers, and how do you deal with them? There are two ways:
- Visual approach – Creating box plots and scatter plots so you can see the outlier
- Statistical approach – Using z-score or IQR methods to find these outliers statistically
Mistake 3: Handling Data Inconsistency
This is all fine, but quite often, you can’t even read the data to begin with. It’s a common issue in data cleaning: data inconsistency. In other words, you might have different date formats or case usages, making it very difficult to analyze data.
To fix this, you need to make data formats consistent by:
- Standardizing the data to maintain consistency in terms of format unit and scales
- Automating the work by implementing data validation checks, aka unit tests software developers use for testing features.
Mistake 4: Handling Datatype Issues
It’s not just the format that can cause problems. Data types can, too. Not checking them until it’s too late is also one of the common mistakes in data cleaning. The solution to this is straightforward:
- Inspect, cast, and convert your data types
- Automate by implementing checks to validate data types at various stages of your project.
For example, suppose a DateTime variable like order date is stored as a string. In that case, you will obviously need to cast that as a DateTime data type to enable your calculations and analysis.
Knowing what data types your database can use and which type can be converted to, like in the below matrix, becomes very useful knowledge.

Mistake 5: Handling Duplicate Data
Having duplicates in your data is the most common mistake. It often comes from bad joins or merges, and it ends up blowing your record count. Many data scientists don't do a post-check or post-inspection to ensure no duplicates in the data. Don’t be one!
To dedupe your data:
- Group it so that it’ll deduplicate automatically
- Add checks at every stage of your analysis to prevent unwanted duplicates
If you’re working in SQL, here’s more about data deduplication and other common SQL coding errors.
A Solution to Avoiding All Five Mistakes at Once
What do all five above mistakes have in common? They mainly involve manual inspection of the data and then a manual fix. The solution now becomes apparent: Why not automate as much as possible?
As I said before, software developers have this concept called unit testing. It ensures that their work passes the requirements of the feature that they're trying to build. You should do the same for data science. To be more specific:
- Reduce mistakes – Create scripts that automate all of these data cleaning tasks that are always on repeat at every step of the process.
- Make your process reproducible – Document the data cleaning process to ensure everyone on your team (including you!) knows what business rules logic is being used and can repeat it.
Conclusion
Implement what you learned here, and you’re on a path to success in data cleaning. There’s really no need to keep repeating these mistakes. They are embarrassing but also easy to avoid.
I know data cleaning is not as exciting as creating sexy graphs or ML models. But all data scientist spend their time (and a significant part, to tell the truth!) doing it. Without it, every other stage of a data science project doesn’t exist. So, first, do the groundwork and master data cleaning. Only after that should you learn other, fancier data science tasks.
Share


