Clustered vs. Non-Clustered Indexes in SQL


 Written by:
Written by:Nathan Rosidi
Today’s showdown is clustered vs. non-clustered indexes. Learn more about their features, strengths, and weaknesses, and join us to see who wins this fight.
Fetching data efficiently is of supreme importance in the world of databases. In fact, getting data and doing that quickly is the whole reason why databases exist at all.
One of the tools used to ensure database efficiency is indexes. Let’s dive deeper into what indexes are and how they work in SQL.
Understanding the Importance of Indexes in Databases
The databases didn’t invent indexing. Books (remember those!?), especially if they’re non-fiction, often have indexes at the end. It’s an alphabetical list of terms and names mentioned in the book and the pages where you can find them, as shown below.


If you want to find Michelle Terry, you don’t need to read the whole book (or at least flick through it). Simply look her up in the index and go to page 129. A task of approximately 15 seconds.
That’s what database indexes are for, too! They allow the SQL query to find the data without scanning the entire table. And tables? There can be many, and they can be gigantic!
Indexes have several significant purposes in databases.
1. Speed and Efficiency: Without indexes, each your attempt to fetch the data from the databases would involve going through the entire table to find that piece of information you need. As we’re working with gigabytes, terabytes, and petabytes of data today, you can imagine how much it could take to scan such data fully.


2. Query Optimization: Indexes contribute to query optimization. If the data in the database is properly indexed, this will reduce the amount of data the query needs to read. For example, if you’re searching for flights from a specific city, the indexed city column will allow the database to return the desired data without checking every single row.
Also, complex queries involve a lot of joining, sorting, and aggregating data. The indexes optimize the order in which tables are joined, reduce the amount of data that needs to be sorted, and facilitate faster aggregation operations.
3. Reduced Load on System: Regularly performing full table scans is very resource-expensive. Indexing reduces the need for that, which saves resources and ensures that the database stays responsive even under heavy loads.
4. Improved Data Integrity: Some indexes, such as unique indexes, ensure data consistency and uniqueness. For example, if you apply the unique index to a Social Security number, it would prevent the possibility of assigning two different users the same Social Security number by mistake.
Clustered vs Non-clustered Indexes in SQL: Brief Overview
There are two main types of indexes in SQL: clustered and non-clustered.
What Is Clustered Index in SQL?
Clustered indexes determine the physical order of data in a table. There can only be one clustered index per table.
What is a Non-Clustered Index in SQL?
Non-clustered indexes are additional indexes that don’t determine the physical order of data. They provide a separate structure that holds data pointers.
Clustered vs Non-Clustered Indexes: Advantages and Characteristics
We’ll now get into the nitty-gritty details of clustered and non-clustered indexes.
Definition and Functionality
Clustered Indexes
As you now know already, a clustered index determines the physical storage order of the data rows in a table. In simpler words, the table’s data is the index. The table rows are organized and stored on disk based on the key values of the clustered index.
The clustered indexes’ functionalities boil down to these four.


1. Physical Ordering: This is the primary functionality ingrained in their definition. These indexes dictate the physical order of data in a table. In other words, the data on disk is arranged in the order specified by the clustered index.
2. Range Queries: These are common queries where you retrieve a range of data. In other words, all the records for a value between two boundaries. For example, you want to fetch all orders between January and May 2023. If there’s a clustered index on a date column, the database can quickly locate the starting date and retrieve the range of consecutive dates/rows.
3. Data Retrieval: With these indexes, there’s no additional lookup to retrieve the actual data. The index key directly corresponds to the data row’s storage location so that data can be retrieved immediately.
4. Uniqueness: It’s beneficial for the key columns of a clustered index to be unique. That’s because a unique identifier ensures that each row can be distinctly located. If there are no unique keys, the database will often automatically add a unique identifier.
Non-Clustered Indexes
These are indexes that are a separate structure from the table with data. Non-clustered indexes contain a sorted list of key values, with each key value holding a pointer (often a row locator) that points to the corresponding row in the table where the actual data is.
From this definition arise non-clustered index functionalities.


1. Separate Structure: The index is not the data itself but a separate entity. This results in the possibility of having multiple non-clustered indexes on a table, with each index being optimized for different query patterns.
2. Data Pointers: When there’s a non-clustered index, the database first finds the relevant key value in the index. Then, it follows the pointer to the actual data row. If the table has a clustered index, this pointer is the clustered index key. If not, it's a row identifier (RID) pointing to the row's physical location.
3. Covering Index: The covering index is a particular type of non-clustered index. It includes all the columns referenced in a specific query. When a query can be satisfied entirely using the covering index without the main table, it can significantly boost performance.
4. Flexibility: They offer flexibility in optimizing specific query patterns. For example, if you frequently query both name and location columns, separate non-clustered indexes on both columns can ensure fast data retrieval for both query types.
Structure and Organization
The indexes in SQL are typically implemented using a B + tree structure. We won’t go into details about its properties. We’ll just show you how it works in the context of indexes.
To understand how indexing works, it will suffice to say that the B+ tree is a version of a tree structure used in databases for storing, searching, inserting, and deleting data.
Let’s now see the general example of how the B+ tree structure is used for database indexing.
There are four important terms you need to know.
- Root node – A top node without a parent
- Internal nodes – Nodes that have children nodes
- Leaf nodes – Noddes that don’t have children nodes
- Key – Values stored in nodes

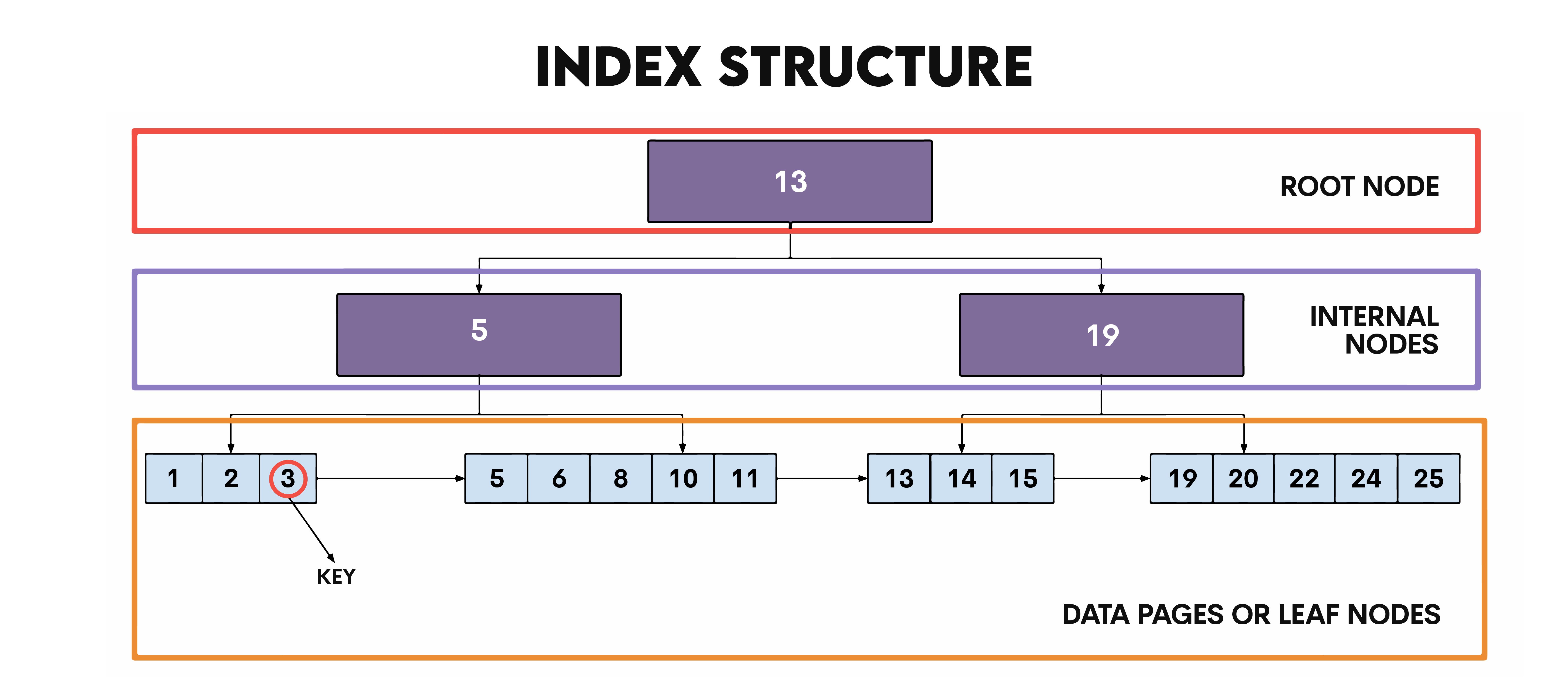
Looking for a certain value looks like this. Say, we’re looking for the value k = 10. It’s first compared with the root node; k < 13. So the database now knows it has to go to the left internal node and can completely ignore the right one. It now compares k with the internal node; k > 5. Now, it ignores the left leaf node, and goes to the right one. There, it will find 10 among the other four keys.
This quite obviously shows how this structure allows indexes to find the data quickly, as database doesn’t have to go through all the data rows until it reaches the targeted one.
Let’s now look at the distinct structure and organization of the clustered and non-clustered indexes.
Clustered Index
Let’s imagine we have a table with 1,000 rows. This table has a clustered index. Its structure consists of index rows and data rows, which can be represented like this.

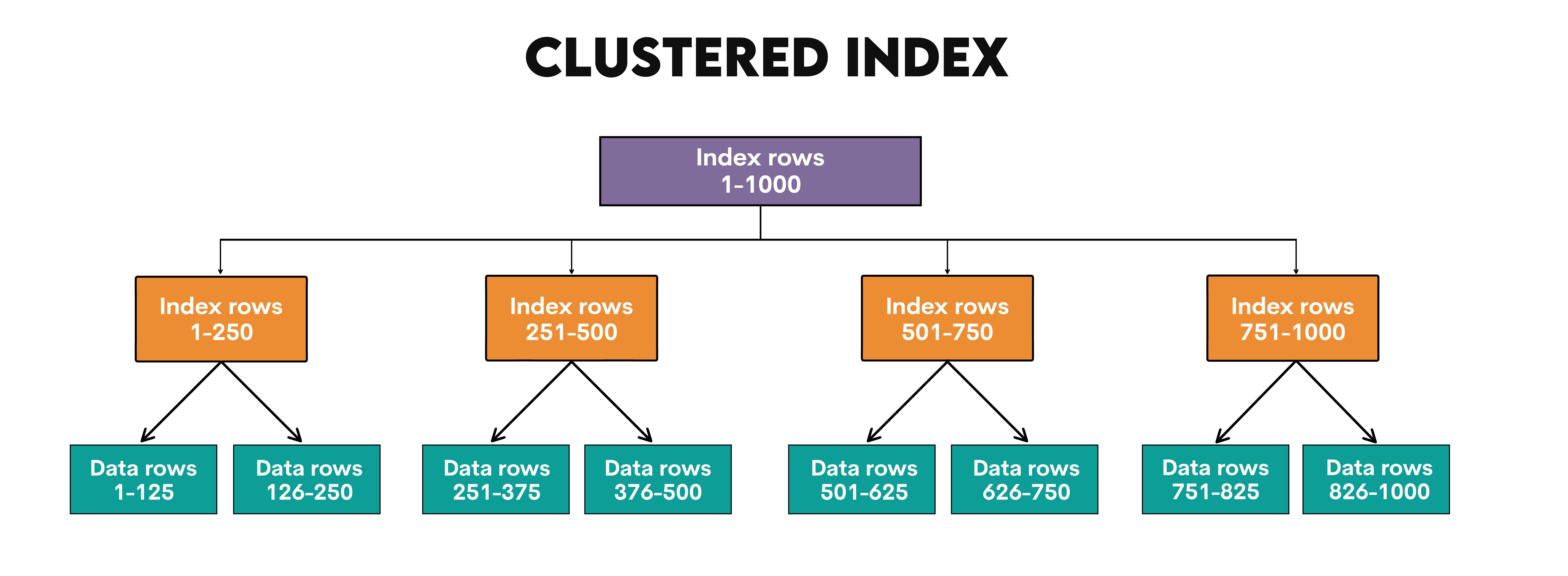
Data search starts from the root node, which points to four intermediate nodes. Each intermediate node then points to data pages that contain actual data of specified rows. Every data page contains – and this is just an example – 125 rows of the table.
We’ll show how this works in practice in the later section of the article.
Non-Clustered Indexes
Now, the non-clustered index’s structure is similar to the clustered index. However, non-clustered indexes don’t have index and data rows. Instead, there are key values and row locators.


The data search starts from the key values root node. They point to a specific internal node, which then points to the particular node that holds the info about in which row of a table to find a value.
After that, the database uses the clustered index to find this data in the table. So, as you can see, a non-clustered index works together with the clustered index to improve data retrieval performance.
We’ll see how they do that in the later section. But first, let’s talk about the advantages of these indexes.
Advantages Offered
Let’s now talk about the advantages each of these two indexes offers.
Clustered Index
1. Efficient Data Access: Since the clustered index defines the physical order of data, it allows for efficient access, especially for queries that retrieve ranges of data.
2. Reduced I/O Operations: Accessing data in a clustered index often requires fewer I/O operations because the data rows are stored sequentially.
3. Optimized for Range Queries: Ideal for queries that retrieve data within a certain range, as the data is already sorted.
4. Faster Data Retrieval for Sorted Data: When data needs to be retrieved in a sorted order matching the index, it's faster as the data is already physically ordered.
Non-Clustered Index
1. Flexibility for Multiple Indexes: You can create multiple non-clustered indexes on a table, each optimized for different queries.
2. Efficient for Specific Queries: Ideal for queries that involve searching for specific values in indexed columns.
3. Minimal Impact on Data Insertion: Unlike clustered indexes, non-clustered indexes have less impact on the performance of data insertion, as they don't dictate the physical order of the entire table.
4. Covering Indexes: Can be used to create covering indexes, where the index contains all the fields required by a query, leading to faster query performance.
When to Choose
Knowing all these technicalities about indexes is necessary to know which one to choose.
Clustered Index
1. Primary Key Scenarios: Often used for the primary key of a table, as it ensures uniqueness and efficient access.
2. Range-Based Queries: Ideal for scenarios where you frequently need to retrieve data in a specific range, like dates or sequential numbers.
3. Tables with Frequent Sorted Data Retrieval: When the common use case involves retrieving data in a sorted order that aligns with the clustered index.
Non-Clustered Index
1. Tables With Diverse Query Patterns: When your table is accessed using a variety of query conditions, non-clustered indexes can be tailored to optimize these different queries.
2. Columns Used in Joins and WHERE Clauses: Ideal for columns that are frequently used in JOIN operations or as conditions in WHERE clauses but are not part of the primary key.
3. Need for Additional Indexes: When the primary key is already using a clustered index, and there's a need for additional indexes for query optimization.
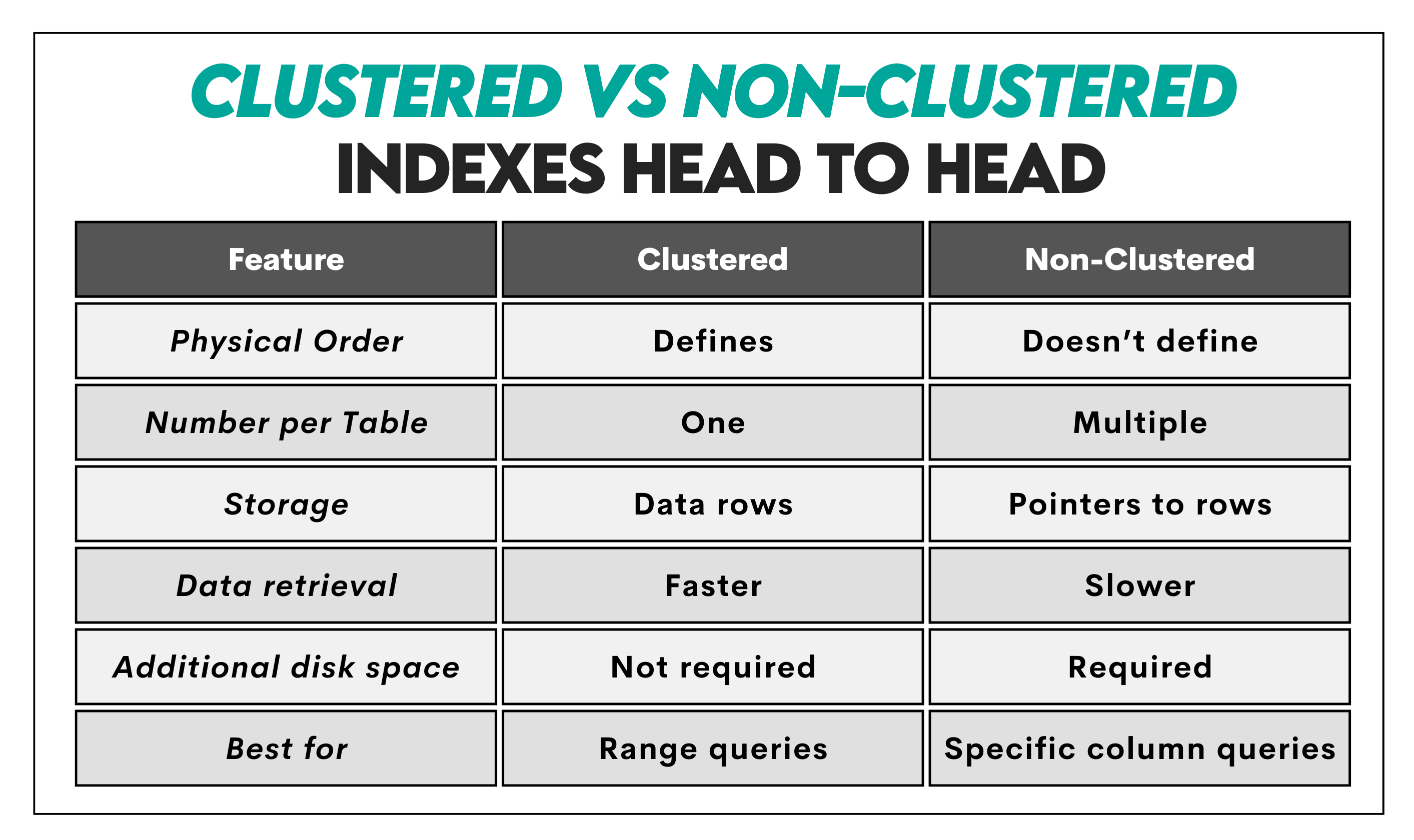
Clustered vs Non-Clustered Indexes: Head-to-Head Comparison
Here’s a head-to-head comparison of the two types of indexes.

Clustered vs Non-Clustered Indexes: Practical Example
Clustered Indexes
Let’s work with the below table named customers. It has 1,000 rows with the following data.


The id column is the table’s primary key. Creating the primary key automatically turns this column into a clustered index.
We want to find the data for the customer whose id = 624. This is how the clustered index does that.


The customer with id = 624 can be found in the leaf node where the data for rows 501-625 are stored. Once the database locates the correct leaf node, it will go through all the data in this node until it finds the customer with id = 624, which is Jamie Semorad, and show all the data for that customer.
Non-Clustered Index
We’ll use the same table as above to show how the non-clustered index works.
The table already has the clustered index on the column id. Now, we add the non-clustered index on the column last_name.
This means we now have two indexes on a table: primary (clustered) and secondary (non-clustered).


To find the last name Semorad, the query looks for it in key values. Since they are sorted alphabetically, the database knows that the surname is somewhere in the right part of a tree. It then finds the surname in the last key values block on the right. After that, it finds the surname and the pointer to the row where the data can be found.
The query then goes to the clustered index. It now knows that the required data is to be found in row 624. So, it performs a search through the index tree as we showed earlier: it goes through branches of index rows until it reaches the data page where all the data for row 624 is. When it finds row 624, it will output all the columns from that row.
Clustered vs Non-Clustered Indexes: Limitations and Best Practices
Both of these indexes have, of course, their limitations and best practices that should be considered when using them.
Clustered Index
Limitations


1. Single Index Per Table: Only one clustered index can be created per table, as it defines the physical order of data. This limitation requires careful consideration when choosing which column(s) to index.
2. Insert and Update Overhead: Inserting or updating data can be more time-consuming, especially if the new data disrupts the existing order. The database might need to move data to maintain the order, which can be resource-intensive.
3. Fragmentation Issues: Over time, as data is inserted and deleted, the table can become fragmented. This can potentially impact performance as the physical order of rows becomes scattered.
Best Practices


1. Use for Primary Key: It's often beneficial to create the clustered index on the primary key, especially if it's a monotonically increasing value (like an auto-incremented integer), which minimizes fragmentation.
2. Consider Range Queries: Choose a column (or columns) that are often used in range queries, such as dates, sequential numbers, etc., for the clustered index to leverage its efficiency in these operations.
3. Avoid Volatile Columns: Avoid using columns with frequently changing values as the clustered index key because each change can necessitate data movement.
4. Regular Maintenance: Implement regular maintenance tasks like defragmentation and table reorganization to manage fragmentation and maintain optimal performance.
Non-Clustered Index
Limitations


1. Additional Disk Space: Non-clustered indexes are stored separately from the table data, requiring additional disk space. This can be a significant factor in databases with a large number of indexes or large datasets.
2. Write Performance Overhead: While non-clustered indexes improve read performance, they add overhead to write operations. Each insert, update, or delete in the table may require corresponding changes in the non-clustered indexes.
3. Over-Indexing: Creating too many non-clustered indexes can lead to performance degradation. Each additional index increases the complexity and time required for write operations.
Best Practices
1. Index Columns Used in Queries: Create non-clustered indexes on columns frequently used in WHERE clauses, JOIN conditions, or ORDER BY clauses. This optimizes query performance by reducing search time.
2. Limit the Number of Indexes: Carefully evaluate the necessity of each non-clustered index. Analyze query patterns and remove indexes that do not provide a significant performance benefit.
3. Use Covering Indexes: For queries that access only a subset of columns, consider creating covering indexes that include all these columns. This can significantly reduce I/O by eliminating the need to access the table data..
4. Monitor Index Usage and Performance: Regularly monitor the performance impact of non-clustered indexes and review their necessity, especially after significant changes in the application's usage patterns.
General Best Practices for Both Index Types
1. Regular Index Maintenance: Perform regular index maintenance, including reorganizing or rebuilding indexes, to maintain optimal performance.
2. Balance Between Reads and Writes:
3. Use Indexing Wisely: Indexing should be based on actual data usage and query patterns, not just on theoretical best practices.
4. Test Changes in a Staging Environment: Before implementing changes in a production environment, test the impact of adding or removing indexes in a staging environment.
Conclusion
Indexes are considered more advanced SQL concepts. You’re expected to know them if you consider yourself an SQL expert.
We can help you achieve that. In our blog, there are many articles about advanced SQL concepts, such as this SQL cheat sheet or the one that goes through all the important topics you need to know for the SQL interview questions.
Share


