Basic SQL Interview Questions

Categories:
 Written by:
Written by:Nathan Rosidi
In this article, we will go over some basic SQL interview questions asked during the interviews and how to approach solving them easily.
Aspiring data scientists already know that writing SQL queries is one of the necessary skills to do the job. In this article, we will go over some basic SQL interview questions asked during the interviews. By the time you’re done reading it, you should have a good understanding of how to approach common SQL interview questions and solve them easily.
Throughout the article, we will also pinpoint the most important concepts you must know to solve the tasks. These questions are still in circulation at top organizations today, so you’ll be getting a fresh perspective on the interview process for data science positions.
Our solutions to the SQL interview questions are not only correct but optimized. This is important, because employers look for candidates who write simple, yet effective queries. Our recent article “How to write SQL queries“ focuses on how we can improve our SQL queries in particular when it comes to performance and readability.
Writing SQL queries during the interview can be a stressful task. The process gets easier once you understand all the concepts behind basic SQL interview questions. In the section below, we’ll look at concepts of various levels of difficulty (beginner to intermediate).
Basic SQL Concepts Tested in Interviews

Before trying to answer basic SQL interview questions, you must have a good understanding of fundamental principles. Some of these SQL statements are key building blocks of advanced queries.
1. Aggregate functions
Standard SQL contains several important aggregate functions. These are going to be useful regardless of the difficulty of the task. Most of the time, you’ll have to use them in combination with CASE statements.
There are five important aggregate functions in sql: COUNT(), SUM(), AVG(), MIN(), and MAX(). As the name suggests, they’re used to aggregate the values within columns.
The knowledge of how to use them will be extremely useful towards getting a data scientist job. Aggregate functions are also essentials to perform well on the job once you are hired.
2. JOINs
Most of the time, companies do not store their data in one giant table, but several logically separated ones. Even junior data scientists are expected to know how to work with multiple tables. That’s why the knowledge of JOIN statements is so important. Every candidate should know about different types of JOINs, how to make use of ON statements and how to give tables an ‘alias’. Our post “SQL JOIN Interview Questions” covers the most common questions and what you need to know about JOINs to ace your interview. Also, check out “How to Join 3 or More Tables in SQL” where we talked about using a commonly required SQL concept.
3. GROUP BY
In SQL, the GROUP BY clause allows you to organize the results of aggregate functions. For instance, you might have several years of data and need to aggregate values for each year. In this case, you are dividing the overall aggregate data into several groups - each group represents one year. You can create groups with more than one column.
GROUP BY clause is often used with aggregate functions. It is an essential part of any data scientist’s toolkit.
4. ORDER BY
At first glance, the ORDER BY clause is a fairly simple concept. Still, it’s important to master to do well during the interviews and fulfill your duties on the job. ORDER BY is usually used with ASC and DESC keywords. It has default patterns for ordering letters and numerical values.
Studying the ORDER BY clause can help you write simple and effective SQL queries. You should know more than the basics, for instance how to order more than one column.
5. SELECT and FROM Statement
These are the two essential building blocks of any SQL query. The SELECT statement is used to specify the columns to view. The FROM statement is used to identify the table that contains the columns. These are the most basic concepts of SQL, and a good place to start if you’re a complete beginner.
6. Date Manipulation
Data scientists often have to work with ‘date’ or ‘datetime’ values. Standard SQL includes multiple functions that allow you to manipulate data. Some of them are basic, such as DAY(), MONTH(), and YEAR(), which return the respective time units of a given date value.
For instance, if you want to get just a year value of a broadly formatted date value, you can use the YEAR() function. More advanced functions include DATE_PART(), EOMONTH(), or FORMAT(). If you want to gain a deeper understanding of date manipulation in SQL, look at practical examples in this post “SQL Scenario Based Interview Questions”.
7. DISTINCT
Normally used with SELECT statements, the DISTINCT keyword allows you to specify that you only want to view unique values. This is often useful if the task at hand requires selecting unique values. Often it is used with the COUNT() aggregate function to get the number of unique values in a column.
Basic SQL Interview Questions
Let’s move on to some basic SQL interview questions asked during the interviews.
Basic SQL Interview Question #1: Total Cost of Orders
In this question, candidates must find the total cost of every customer’s orders. We have two tables of data to work with, named ‘customers’ and ‘orders’. The final result should be a table with three columns: customer’s id, his or her first name and total volume of their order. The question includes one more condition: the records must be ordered alphabetically, based on customer name.
Total Cost Of Orders
Last Updated: July 2020
Find the total cost of each customer's orders. Output customer's id, first name, and the total order cost. Order records by customer's first name alphabetically.

Link: https://platform.stratascratch.com/coding/10183-total-cost-of-orders
Basic SQL Concepts to Solve This Question
This question involves calculating a total volume of orders based on certain criteria. To calculate total values, we’re going to need aggregate functions, specifically SUM(). We also can not do without the SELECT statement.
If we take a look at the task description, we have two tables. Both contain the data necessary to produce our final output. So the question requires a good knowledge of JOINs as well. To summarize the aggregate data into multiple groups, we must use GROUP BY statements as well.
The last requirement is to order the values based on certain criteria. For that, candidates will need to use ORDER BY statement.
Available dataset
Data Assumptions
Most of the time, basic SQL interview questions don’t spell out every detail necessary to complete a task. Candidates must make their own assumptions and double-check with interviewers to make sure they’re staying on the right track.
Most of the time, descriptive column names do a good job of communicating the purpose of a column. In our example, we know that the total_order_cost column represents total cost, not cost per item.
In our example, the two tables contain the necessary values to produce final output. We can assume that the two tables will need to be joined. A candidate must also decide which fields are important and which can be safely ignored. In our example:
- the id column of the customers table represents customer id. Our final output includes this value, so it is important. It is identical to the cust_id column from the orders table. In our solution, we’ll use the latter
- first_name column of the same table - our output includes the first_name value as well.
- last_name, city, address, phone_number - these values are not in the expected table, so we can safely ignore them.
- The id column of the orders table represents order ID. It is not useful for solving this question
- cust_id column contains a value that we are going to use.
- order_date is not important, because the question doesn’t involve any date-time manipulation or sorting of orders by date.
- order_details is also unimportant, because the question doesn’t ask about the nature of the orders.
- total_order_cost column is important. We are going to aggregate the values from this column.
In this case, we selected cust_id to identify the customers instead of id from the customers table. The reason for this is that cust_id is a more readable column name. If you make decisions that aren’t obvious, you should explain your reasons.
Depending on the nature of the task, you might think of multiple solutions. It’s important to ask questions like, whether or not you’re limited to standard SQL. Sometimes a function or clause from PostgreSQL might be much more efficient. The interviewer might give you a hint if they’re looking for a specific solution or a function.
In general, it’s a very good idea to discuss your assumptions with the interviewers. It shows your understanding of the question and the depth of your sql knowledge.
Solution Logic
Once we understand the data at our disposal, writing sql queries becomes fairly straightforward. Looking at the question description, it’s easy to plan our next steps:
- Select the cust_id, first_name and the sum of total_order_cost
- Join the two tables, and specify that id column in customers table and cust_id column contain the same values
- Use GROUP BY statement to display customers that have both unique first names and unique id-s.
- Use ORDER BY to rank the first names alphabetically.
Knowing the aggregate functions inside out will help your chances of landing a job. In this basic SQL interview question, the last column will be an aggregate of all orders. You don’t need to specify the label for the column. TheSUM() function automatically assigns the column the label ‘sum’.
To effectively answer this question, you must also know why table joins are necessary and how to perform them. Also, how to join the tables that have columns with the same values.
Understanding of the GROUP BY statement will help you handle all edge cases successfully.
For example, what if there are two different customers with the same first name? After all, in real life, there’s a very high chance that this will happen. The cust_id is a unique customer identifier and chaining it with the first name eliminates the chance of any errors. This is useful if there are two customers with the name Mary. Using GROUP BY with cust_id as well as first_name helps us avoid lumping their order volumes together.
In comparison, the ORDER BY is more straightforward. You only have to select a field (in our example, first_name value) and assign one of the ASC or DESC keywords. We need to order the letter values alphabetically, so we use ASC.
Solution
First, we must select the fields for output. These are, first_name, cust_id and an aggregate sum of total_order_cost values. The third column will be automatically labeled as sum. So far, our query should look like this:
SELECT cust_id,
first_name,
sum(total_order_cost)Then we must write the FROM statement and join the tables.
SELECT cust_id,
first_name,
sum(total_order_cost)
FROM customers
JOIN orders ON customers.id = orders.cust_idNow we need to calculate the total order volume for each customer. For that, we’re going to use a GROUP BY statement. We’ll group by both the cust_id and first_name values to avoid lumping two different customers with the same names.
SELECT cust_id,
first_name,
sum(total_order_cost)
FROM customers
JOIN orders ON customers.id = orders.cust_id
GROUP BY cust_id,
first_nameIf we run this code, our output table will look like this:
| cust_id | first_name | sum |
|---|---|---|
| 12 | Eva | 205 |
| 4 | William | 140 |
| 5 | Henry | 80 |
| 15 | Mia | 540 |
| 1 | Mark | 275 |
| 7 | Jill | 535 |
| 3 | Farida | 440 |
As a last step, we must use the ORDER BY statement to organize the values alphabetically. To do this, we should use the ASC keyword. When applied on values that contain letters, the ASC keyword orders them alphabetically.
SELECT cust_id,
first_name,
sum(total_order_cost)
FROM customers
JOIN orders ON customers.id = orders.cust_id
GROUP BY cust_id,
first_name
ORDER BY first_name ASCThat’s the final answer to the question. Here’s what our final output will look like:
| id | first_name | sum |
|---|---|---|
| 12 | Eva | 205 |
| 3 | Farida | 440 |
| 5 | Henry | 80 |
| 7 | Jill | 535 |
| 1 | Mark | 275 |
| 15 | Mia | 540 |
| 4 | William | 140 |
Once you’re finished with easy questions like this one, some interviewers might ask you to perform more advanced operations on top of what you’ve already done. They might add more edge cases. For example, what if the total_order_cost field is empty?
Basic SQL Interview Question #2: Unique Users Per Client Per Month
The requirements of this basic SQL interview question are very clear: the candidate has to write a query that returns the number of unique users for every client per month. We have a fact_events table which includes all the information necessary to solve this task. It includes seven fields, some of which are going to be necessary, while others can be ignored. Scanning the table to find the necessary columns can be a very useful skill when solving sql interview questions.
The outputted table must include three columns: client identifier, month, and corresponding number of unique users. The question is marked as ‘Easy’ on StrataScratch, but it can be tricky. If you get stuck, you use hints available on the question page.
Unique Users Per Client Per Month
Last Updated: March 2021
Write a query that returns the number of unique users per client for each month. Assume all events occur within the same year, so only month needs to be be in the output as a number from 1 to 12.
Link: https://platform.stratascratch.com/coding/2024-unique-users-per-client-per-month
Basic SQL Concepts to Solve This Question
To solve this task, we’ll have to use the COUNT() aggregate function. The question specifically asks for unique users, so we’ll use the DISTINCT clause in combination with the aggregate function. Also, the data needs to be divided into several groups, so GROUP BY statement will be necessary.
In the fact_events table, there is only one datetime value, but the question asks for users per month. The month value can be extracted from the time_id field. To do this, we’ll need the DATE_PART() function in PostgreSQL or the standard SQL alternative - DATE_FORMAT() function.
Available dataset
Data Assumptions
The question has fairly specific conditions and requirements. Still, the whole description consists of one sentence, so there’s some room for interpretation. Some assumptions are natural, while other times you have to confirm your assumptions with the interviewer.
Since this basic SQL interview question is very short, every word carries higher significance. In this case, not paying attention to one single word could set you on the wrong track. For example, the question asks you to return the number of unique users. The word ‘unique’ is the keyword here. Similarly, we should pay attention to the ‘per’ keyword, to properly arrange the output table and its columns.
This keyword also tells us that we’ll be doing aggregation based on certain fields and GROUP BY keyword is going to be necessary. The question asks for the total number of unique users, so it’s clear that you’ll be aggregating the users.
If you’re straight out of college, it might take you some time to figure out where the values should come from. If the original table you’re working on has confusing column labels it’s okay to ask the interviewer to confirm. However, it’s always better to get it right on your own. Let’s look at the columns in our example and their respective data types:
- id column, in this example, represents an unique identifier for every record. Since we’re not keeping track of records, it can be ignored.
- The time_id column is useful and important, since it is the only datetime value in our table. We will use it to extract the month values.
- user_id is also necessary, because we’re keeping track of users.
- customer_id field can be safely ignored, because our task doesn’t involve keeping track of customers.
- client_id, is necessary, because the task involves keeping track of monthly users for every client
- The question doesn’t mention anything about events, so event_type and event_id fields are irrelevant.
Once we review these columns, selecting the necessary data becomes much easier. There’s just one problem - the datetime value in the time_id column includes year, month and day in a specific format. Let’s take a look at the example:
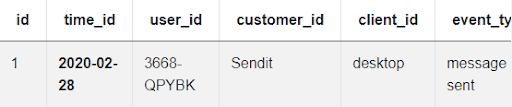
We’ll need to extract the month value to sort unique users by month. To do that, we can either use DATE_PART() in PostgreSQL, or its alternative DATE_FORMAT() in standard sql. It’s a good idea to specify with your interviewer whether or not you are allowed to use the functions from specific SQL dialects, such as PostgreSQL.
Based on the wording of the task, it’s safe to assume that the data is collected from one specific year. Otherwise, extracting months from multiple years of data without specifying the year would lead to errors.
Solution Logic
Understanding the data at your disposal is key to solving all sql questions. Once we understand the requirements of the task, we can come up with a course of action. The solution is going to involve four broad steps:
- Select the columns we need for the output table: client_id, time_id, user_id from the fact_events table
- use DATE_PART() to get a month value from time_id column
- use COUNT() to aggregate the number of unique users based on the user_id field.
- Finally, group the aggregate of users by client_id and the extracted month
Pay attention to the way the question is phrased. Don’t miss the fact that you have to count only unique users. You’ll need the DISTINCT keyword to do that. Many basic sql interview questions are designed to test your attention to details when you’re under pressure. Don’t just scan the requirements or gloss over the details. Read them carefully.
The knowledge of date manipulation functions is going to be useful here. If you’ve used functions like DATE_PART() or DATE_FORMAT() at least once, you’ll have an easier time solving this basic SQL interview question. You must be familiar with their syntax, what arguments they take and what kind of value they return.
For instance, DATE_PART() returns the order of the month in the calendar year. For example, DATE_PART(‘month’, ‘2020-01-01’) will return the order of January in the calendar year, which is 1.
Solution
As a first step, we select the fields that contain essential data, and specify the table:
SELECT client_id, DATE_PART('month', time_id) as month, COUNT(DISTINCT user_id) as users_num
FROM fact_events
There’s a lot going on here. We must extract months from the values in the time_id column. In PostgreSQL, we do that using the DATE_PART() function. Then we use the COUNT() aggregate function to get the number of users, and use the DISTINCT clause to only count the unique ones.
SELECT client_id, DATE_PART('month', time_id) as month, COUNT(DISTINCT user_id) as users_num
FROM fact_events
GROUP BY 1,2Ultimately, we specify the criteria for GROUP BY statements. We could write out the names of the two columns, but it looks much cleaner this way.
If we run this code, this is the output we are going to get:
| client_id | month | users_num |
|---|---|---|
| desktop | 2 | 13 |
| desktop | 3 | 16 |
| desktop | 4 | 11 |
| mobile | 2 | 9 |
| mobile | 3 | 14 |
| mobile | 4 | 9 |
Summary
As a data scientist, your day-to-day job will be writing simple queries. Sure, with enough experience, you’ll be able to step in when complex solutions are needed. But it is essential to have a mastery over basic sql operations to be good at your everyday job. Most of the queries revolve around the basic concepts, keywords and clauses used in the article.
To pass any interview for a data science position, you’ll have to answer basic SQL interview questions. For candidates, this is an opportunity to show off their proficiency in SQL. Interviewers can judge a candidates’ practical and theoretical skills by looking at their answers.
Sometimes, the task will start off easy, and then the interviewers gradually add more nuance to the question as you go through it. So in order to improve as a data scientist, you must have a thorough understanding of basic sql concepts. Practical experience of writing these queries can get you a job, and more importantly, allow you to keep it.
We also recommend checking our “ultimate guide to SQL interview questions” that will take you through the top questions for various data positions.
Companies are looking for data scientists who write simple, yet effective queries. Knowing how to structure your code is the key to composing more advanced queries. If you still feel like your knowledge of basic sql concepts is lacking, strengthen your core basics before moving on to more advanced concepts.
Share