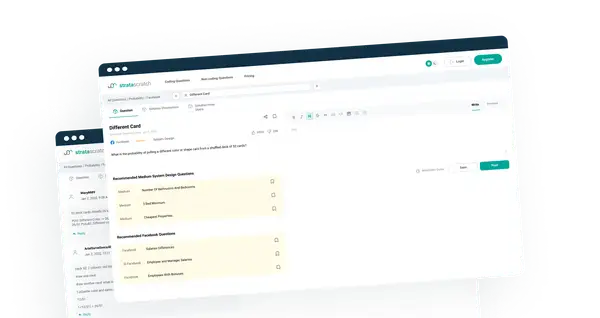
Master coding
for data science
StrataScratch is a data science platform with over 1,000+
real interview questions from your favorite companies
New interview questions are released every month


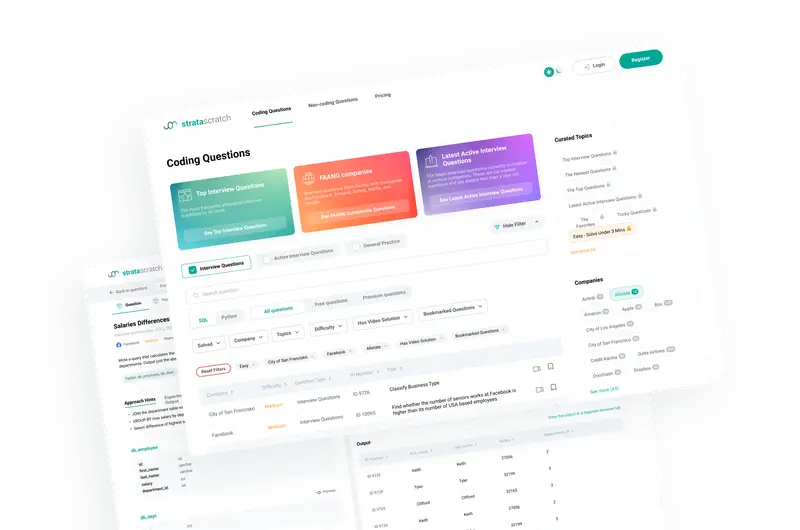
500+ Interview Coding Questions From Your Favorite Companies

Features
Building Blocks For A Successful
Career In Data Science
Tracking interviews from your favorite companies
Track real interview questions from your favorite companies with regular updates
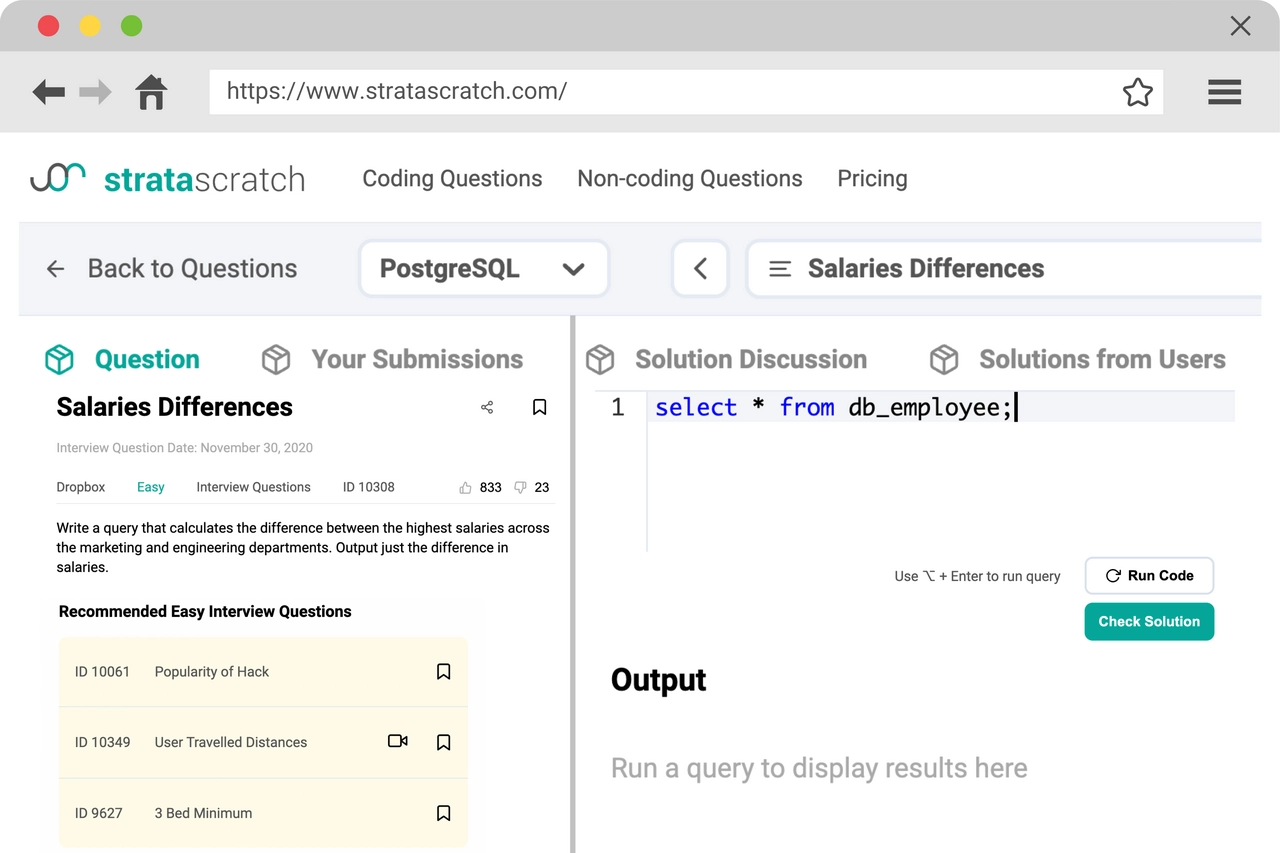
Code in SQL, python, & R
Code your solutions in SQL and python using our code-execution environment that lets you validate your solution
Real data science problems
We focus on teaching you how to solve real-world data science problems, not just proper coding syntax


Statistics
The Best Place To Master Coding
For Data Science
1,000+
Interview Questions
100,000+
Community Members
200+
Companies Tracked
Blog
Data Science Educational Resources

Python String Methods: Here is How to Master Them
Explore practical examples, learn how to effectively clean and format strings, and harness the power of Python’s memory model to master string operations.


What Does a Machine Learning Engineer Do?
What exactly does a machine learning engineer do, and how? What skills do they need? This article will teach you things you didn’t even know you wanted to know.
What Is PySpark? Everything You Need to Know
The Python List Methods I'll Use As a Data Scientist
What is a Data Analyst? Everything You Need to Know
What are you waiting for?
Start coding now
The first 50 questions are free to solve. Jumpstart your career in data science now.
Start Coding Now